대용량 데이터베이스솔루션 2 (2007년 하반기 스터디)
2. SQL 활용의 당위성
- 왜 우리가 SQL을 잘 활용해야 하는가?
SQL 수행 횟수의 차이
10000건의 데이터를 읽어올 때
- 효율성 : 1건 X 10000번 = 10000건 < 10000건 X 1번 = 10000건
- 이유? DBMS Call이 오버헤드가 된다. (배보다 배꼽이 크다)
 |
| 그림1. DBMS Call |
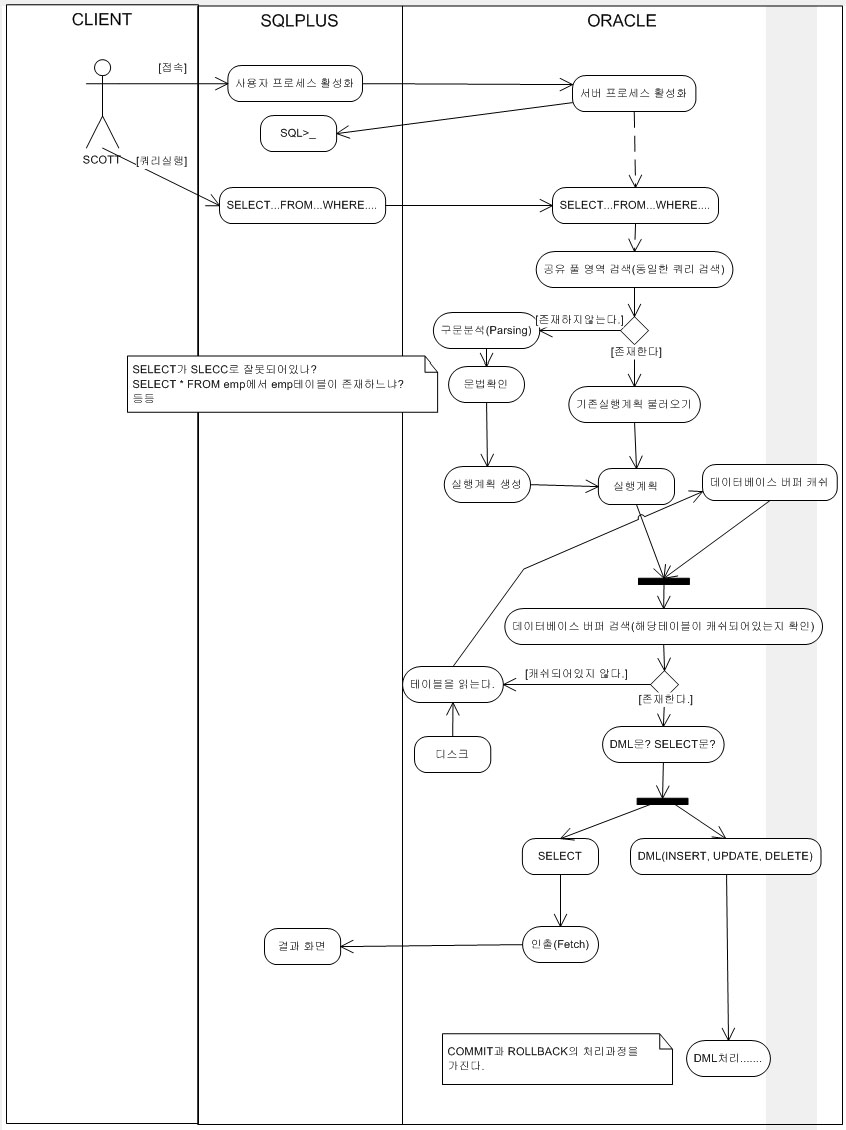
랜덤 액세스 발생량의 차이
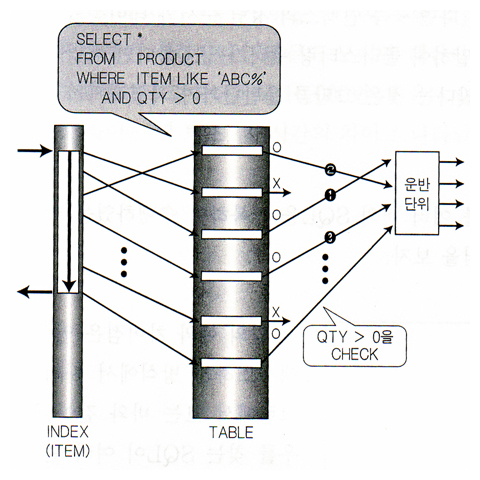 그림2-1. 대용량데이터베이스 솔루션2 1-41 | 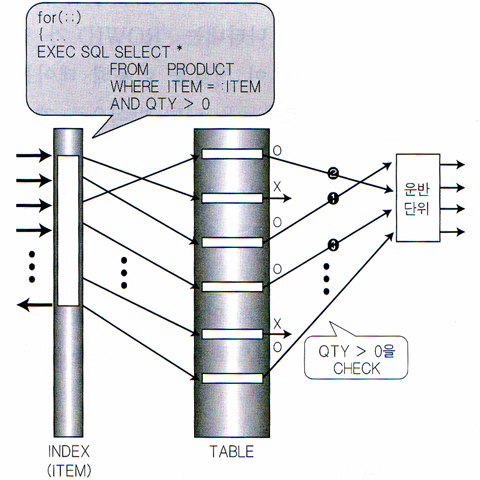 그림2-2. 대용량데이터베이스 솔루션2 1-42 |
| 이유? 운반단위를 빨리채운다 -> 체감속도가 빠르다. | 이유? 운반단위를 늦게채운다 -> 체감속도가 느리다. |
| 왜? ITEM LIKE 'ABC%'는 처음과 마지막에만 검사한다. | 왜? 인덱스의 매 로우마다 ITEM LIKE 'ABC%'를 검사한다. |
| 서버프로세스 : "인덱스야 너 ITEM이 "ABC"로 시작하는곳이 어디야?" 인덱스 : "4번" 서버프로세스 : "그럼 끝나는곳은 어디야?" 인덱스 : "135번" 서버프로세스 : "그럼 내가 말안해도 4번부터 135번까지 하나씩 차례대로 줘.." 인덱스 : "응" | <없음> |
| (N번 반복 - 시작) 1. 인덱스 : "여?어" 2. 서버프로세스 : "이 로우의 QTY가 0보다 크냐?" 3. 인덱스 : "응" 4. 서버프로세스 : "그럼 운반단위에 넣어" 5. 인덱스 : "응" 6. 서버프로세스 : "운반단위가 가득 찼어?" 7. 인덱스 : "아니" / "응" ( - 끝) | (N번 반복 - 시작) 1. 서버프로세스 : "인덱스야 너 ITEM이 "ABC"로 시작해?" 2. 불량인덱스 : "응" 3. 서버프로세스 : "그럼 그거줘바.." 4. 불량인덱스 : "여?다!" 5. 서버프로세스 : "이 로우의 QTY가 0보다 크냐?" 6. 불량인덱스 : "그래." 7. 서버프로세스 : "그럼 운반단위에 넣어" 8. 불량인덱스 : "알았어" 9. 서버프로세스 : "운반단위가 가득찼어?" 10. 불량인덱스 : "아니" / "응" ( - 끝) |
인덱스를 쓰면 왜 빠른가?
이분검색(Binary Search)
- 이분검색을 위한 조건은 딱! 두가지
- 중심점의 값이 찾는 값이면 성공
- 없으면 반으로 자른다.
 |
| 그림3-1. Binary Search(Binary Tree Search) |
이진 나무 검색
- 오라클에서 혼돈하는 Binary Tree와 Balanced Tree는 실은...................같은 나무다!
- 이 나무도 조건은 딱! 두가지!
- 커서의 위치의 값이 찾는 값이면 성공
- 찾는값이 작으면 좌측, 크면 우측!! (밑에 "나무를 순회하는다는 점선.."은 살짝...무시하자.)
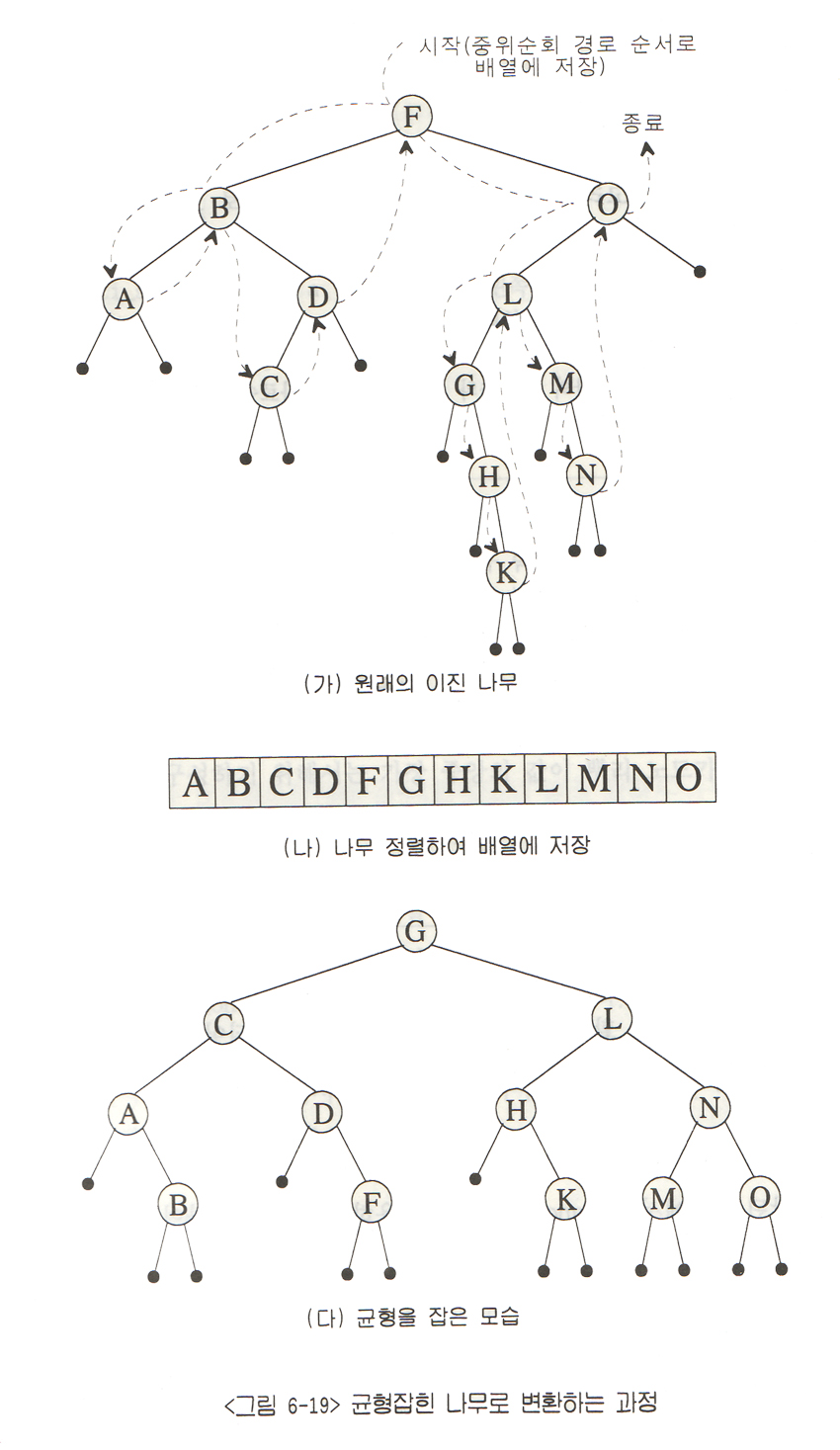 |
| 그림3-2. B-Tree(Binary Tree Search) & B-Tree(Balanced Search Tree) |
이건 샘플.
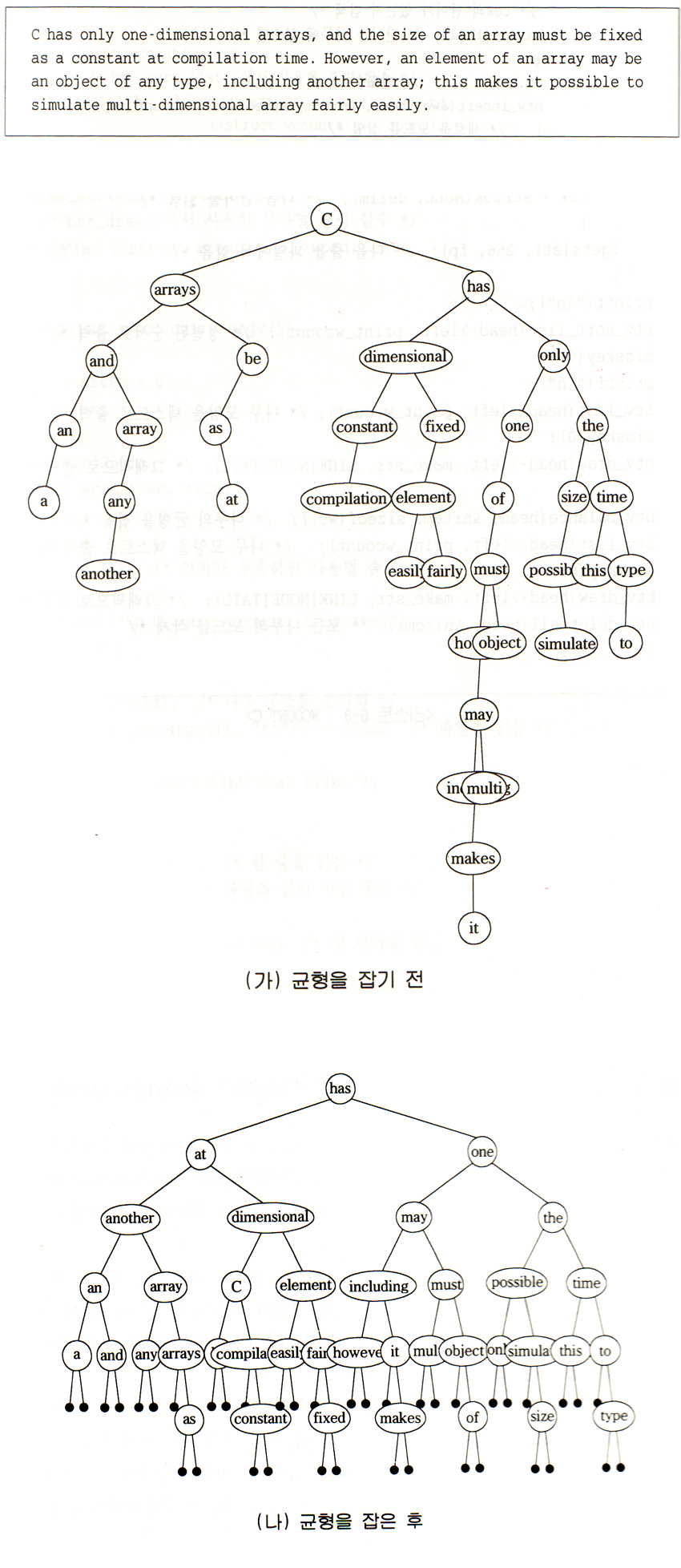 |
| 그림3-3. B-Tree Sample |
처리경로 최적화의 차이
- 옵티마이져 : "난 복합적이고 긴
– SQL문장(절차적+실행적)은 처리 못해." - 그래서? "IF..THEN..ELSE, LOOP"(이하:절차)등 을 사용하여 여러개의 SQL(이하:실행)을 절차형으로 처리하는것이 꼭 좋은것만은 아니다.
- 왜냐하면.. 데이타베이스내에는 절차형을 처리하는 것과, SQL의 실행을 처리하는 것 두가지가 존재한다!
- 그러므로.. 절차형으로 묶어진 실행형 문장들은 한번에 처리되는것이 아니다.
- 옵티마이져 : "사실.. 난 실행단위로만 최적화 시킨다구."
클라이언트/서버환경에서 SQL의 역활
- 대부분의 시스템은 관계형데이터베이스의 장점을 살리지 못하고, 단지 원시적인 읽기와 쓰기의 기능만 사용한다.
- 예를 들어 100,000로우의 데이터를 처리해야할 경우
원시인
- 100,000로우를 데이터베이스로부터 읽어 클라이언트로 가져온다.(데이타베이스I/O, 서버 네트워크 트래픽 낭비)
- 가져온 100,000로우를 클라이언트에서 가공한다.(메모리, CPU낭비, 클라이언트 네트워크 트래픽 낭비)
지성인
- 100,000로우를 처리하는 지혜로운 쿼리를 사용하여, 데이타베이스로부터 어느정도 처리된 결과물을 가져온다. (비싼돈주고산 옵티마이져 활용)
- 서버로부터 가져온 결과물을 클라이언트에서 사용한다.
처리경로 개선의 용의성
절차적 처리
- "IF..THEN..ELSE, LOOP"등과 여러개의 SQL로 구성되어있어, 처리절차를 바꾸기위해 쿼리에 수정이 가해질때에는 전체 구조를 바꾸어야한다.
실행적 처리(추천乃)
- SQL위주로 작성되었기 때문에 SQL과 인덱스의 구조 조정, 힌트의 사용등의 간단한 변경만으로도 처리절차를 바꿀수 있다.
병렬처리에서 SQL의 역할
- 목적 : 얼마나 효율적으로 시스템을 사용할 수 있는가? -> 추가비용을 안쓰고, 소프트웨어만으로 시스템의 퍼포먼스를 올리는 방법 중 하나.
HT(HyperThreading)와 Multi-Core의 차이점!
- Single-Core(HT기능이 없는 CPU)는 한사람이 밥을먹거나, 영화를 보거나 둘중 한가지만 할 수 있는것.
- HT(HyperThreading:intel기술)는 한사람이 밥먹으면서, 영화를 보는 것.
- HT(HyperTransport:amd기술)는 한사람이 밥을 더 큰 숟가락으로 먹는 것.
- Multi-Core는 샴쌍둥이가 협동하는 것.
- 컴퓨터 2대는 두사람이 협동하는 것.
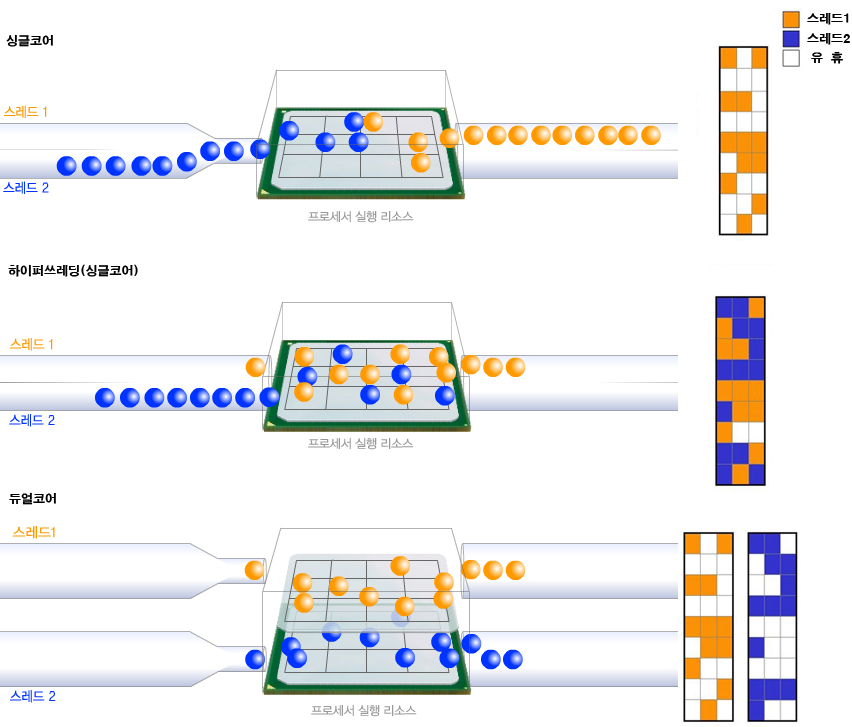 |
| 그림4. 병렬처리의 효율성 |
처리 과정의 파라미터 활용
- SQL만으로 알수있는 것은, 쿼리창에 적혀있는 "요구"(질의)와 "결과"이다.
- SQL만으로는 처리과정을 알수없다.
단순성, 유지보수성, 생산성
- 프로젝트의 전체 비용은 "생산비용 + 유지보수비용" 이다.
- SQL쿼리을 잘 "생!산!" 했다는 것 만으로는 부족하다. 더 나아가 유지보수비용까지 축소시킬수 있는 SQL쿼리를 만들어야한다.
결론
- 완벽에 가까운 SQL쿼리를 만들기 위해 고민해 보아라!!
- 어려운 코드를 이해하는 것과 어려운 코드를 생각해 내는 것은, "책을 읽는 사람"과 "책을 쓰는 사람"의 차이다!
참고문헌
- http://blog.naver.com/etruelove?Redirect=Log&logNo=140028233889
- C로 배우는 알고리즘 (이재규저)
- 강좌 URL : https://www.gurubee.net/lecture/2479
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.