새로쓴 대용량 데이터베이스솔루션 1 (2011년)
Sort Merge 조인
- Nested Loop 조인처럼 각각의 연결할 대상에 대해 일일이 랜덤 액세스를 하지 않으려면 어떻게 하는 방법이있을까?
- 조인할 집합의 대응되는 대상은 서로 알 수 없는 임의의 장소에 위차한다. 이것을 연결 가능하게 하는 방법은 서로 사전 작업을 통해 연결할 수 있는 모습으로 다시 배치를 하게 해야 한다.
- 여기서 연결을 할 수 있도록 사전에 하는 재배치를 정렬(Sort) 방식으로 하여, 이들을 서로 연결(Merge)하는 방식을 Sort Merge 조인이다
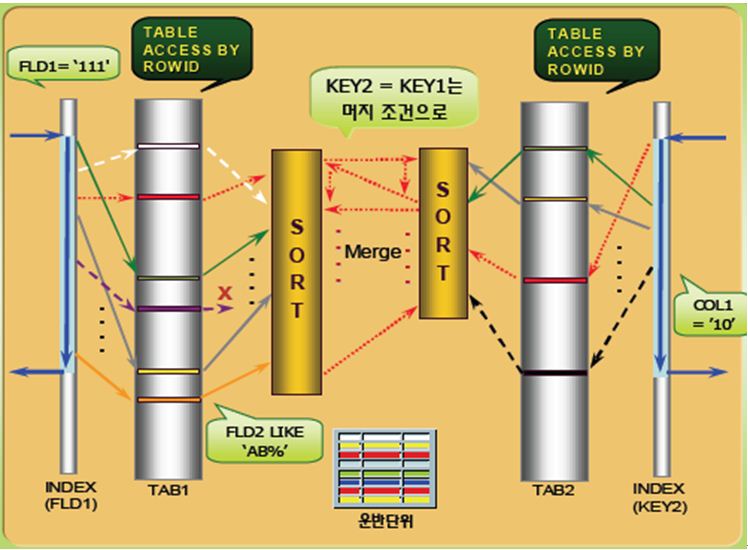 |
- Sort Merge 조인은 그림과 같이 절차로 수행하게 된다.
Sort Merge 조인의 특징 및 적용기준
- 전체범위 처리를 할 수 밖에 없는 프로세싱에서 검토된다(전체범위처리)
- 상대방 테이블에서 어떤 상수값을 받지 않고서도 충분히 처리범위를 줄일 수 있다면 상당한 효과를 기대할 수 있다.(독립적)
- 주로 처리량이 많으면서 항상 전체범위 처리를 해야 하는 경우에 유리해진다.(전체범위처리)
- 연결고리 이상 상태에 영향을 받지 않으므로 연결고리르 ㄹ위한 인덱스를 생성할 필요가 없을때 매우 유용하게 사용할수 있다.(스캔방식)
- 스스로 자신의 처리범위를 어떻게 줄일 수 있느냐가 수행속도에 많은 영향을 미치므로 보다 효율적으로 액세스할 수 있는 인덱스 구성이 중요하다.(선택적)
- 전체범위처리를 하므로 운반단위의 크기가 수행속도에 영향을 미치지 않는다.(무방향성)
- 처리할 데이터 량이 적은 온라인 애플리케이션에서는 Nested Loops 조인이 유리한 경우가많다.(Nested Loop조인비교)
- 옵티마이져 목표(Goal)가 'ALL_ROWS'인 경우는 자주 Sort Merge 조인이나 해쉬조인으로 실행계획이 수립되므로 부분범위 처리를 하고자 한다면 이 옵티마이져 목표가 어떻게 지정되어있는지에 주의하여야한다.(Nested Loop조인비교)
- 충분한 메모리 활용이 가능하고, 병렬처리를 통해 빠르게 정렬작업을 할 수 있다면 대량의 데이터 조인에 매우 유용하게 적용할 수 있다.(Nested Loop조인비교)
Nested Loops 조인& Sort Merge 조인 비교
- 해당SQL를 실행하였을때 두조인에 대해서 비교해보자.
SELECT *
FROM TAB1 A, TAB2 B
WHERE A.KEY1 = B.KEY2
AND A.FLD1 = '111'
AND A.FLD2 LIKE 'AB%' <== 삭제
- Nested Loops 조인으로 수행했을경우 처리철차를 확인해보자
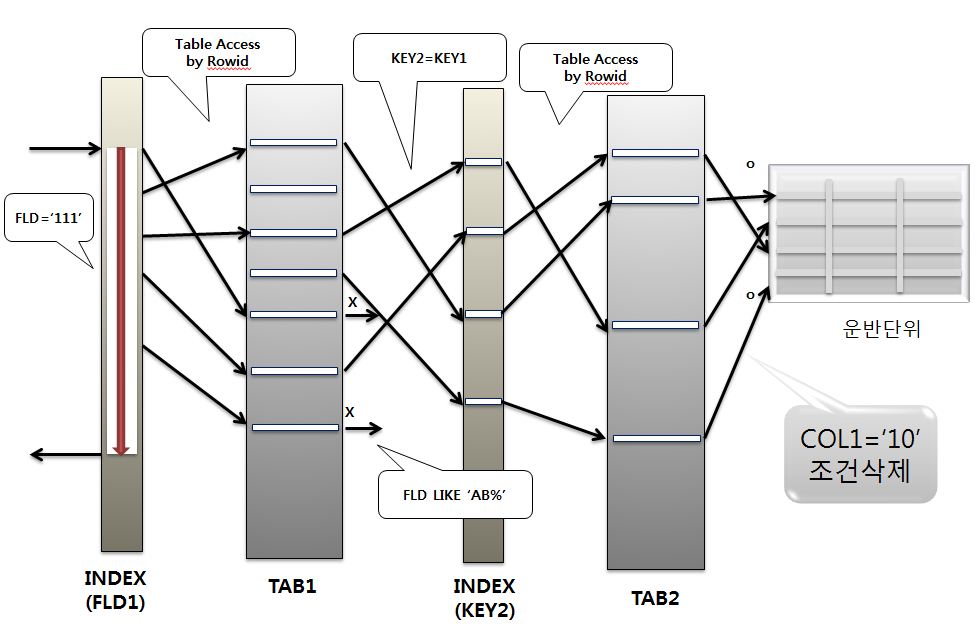 |
- 이 조건은 수행했던 일의 모든조인이 완료된 다음 단지 최종적으로 체크하는 역할을 했다.
- 이 체크 기능이 없어짐으로써 달라진 일은 성공 결과값이 늘어난것이다.
- 이와 같이 Nested Loops 조인에서는 어느 한쪽의 조건이 없어지더라도 영향을 크게 받지 않을 수도 있으며, 경우에 따라서 오히려 유리해질 수도 있다.
- Sort Merge 조인으로 수행을 하였을경우 처리절차를 확인해보자.
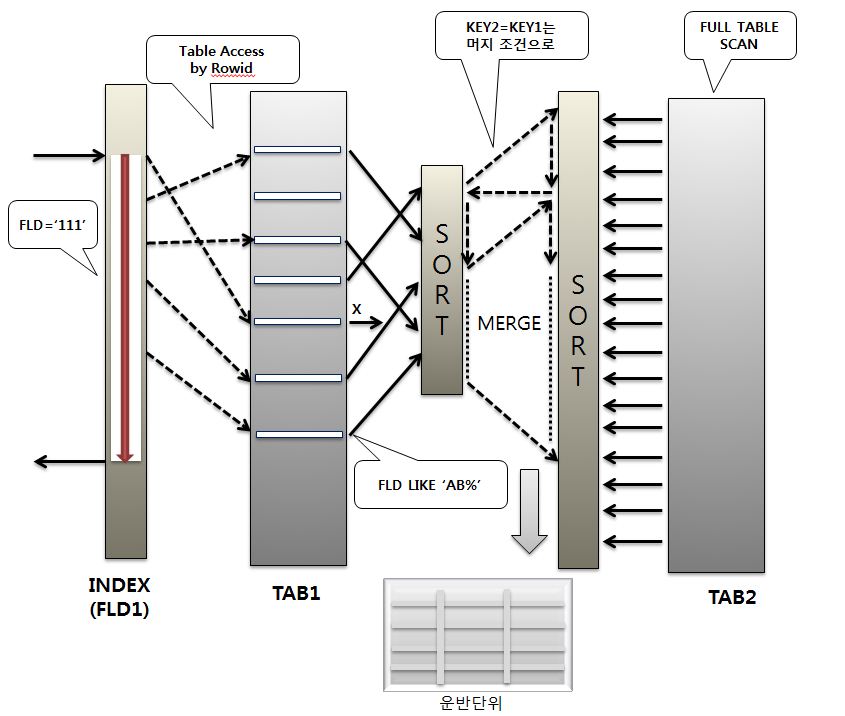 |
- 위와같이 TAB2의 COL1 ='10'인 조건이 빠짐으로써 발생하는 차이를 살펴보자면, Nested Loops 는 TAB2의 처리범위를 줄여 주는 중요한 역할을 했지만,
- 이 조건이 없어짐으로써 이제 TAB2는 전체 테이블을 모두 스캔하여 부담되는 정렬의 범위가 크게늘어나고, 머지할 양도 크게증가하였다.
- 이와 같이 한쪽에 조건을 삭제해 보았더니 nested Loops 조인은 거의 영향은 받지않았으나
- Sort Merge 조인은 엄청난 일의 증가를 가져왔다. 이것으로 두개의 조인의 차이점은 확인할수있다.
- 아래 SQL은 ORDER BY 를 하였으므로 전체범위를 처리하게 될것이다.
SELECT *
FROM TAB1 A, TAB2 B
WHERE A.KEY1 = B.KEY2
ORDER BY A.FLD5, B.COL5
- SQL이 전체범위처리를 Nested Loops 조인으로 수행하였을 때 처리되는 절차를 확인해보자
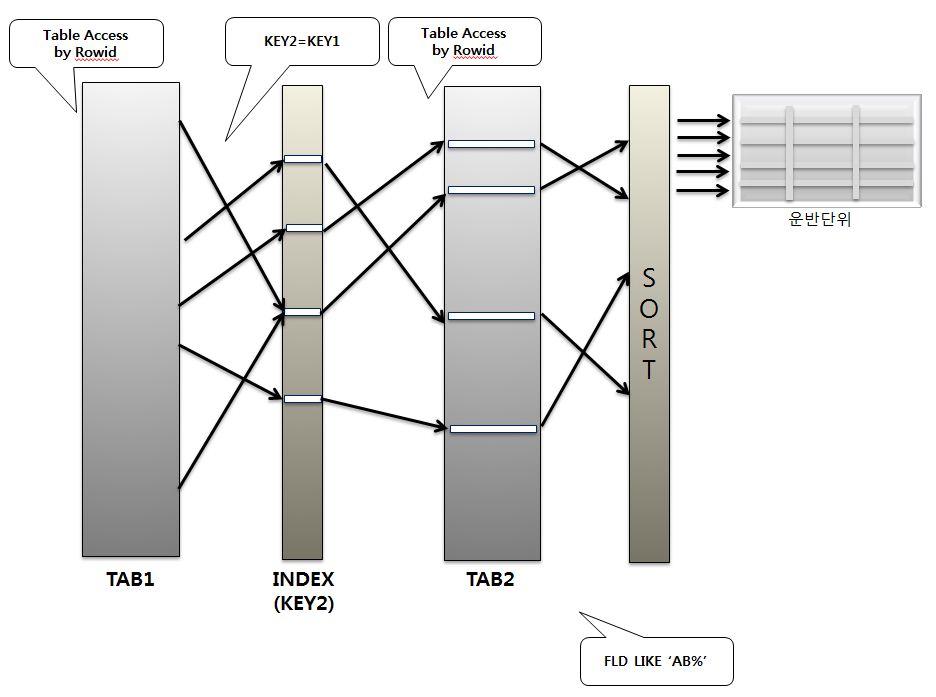 |
- 조인되는 양쪽에 모주 조건이 없으므로 어느 한쪽이 먼저 전체 테이블을 스캔한다.
- 여기서는 TAB1 읽혀진 KEY1의 상수값에 대응되는 로우를 KEY2 인덱스에서 찾아 ROWID로 TAB2의 해당 로우를 액서스한다.
- 이 처리방식은 선행테이블이 전체 테이블을 스캔하므로 전체 테이블을 대상으로 랜덤 액세스가 발생한다.
- 이번에는 동일한 SQL로 Sort Merge 조인으로 수행시켰을 때의 어떤 차이를 내는지 확인해보자.
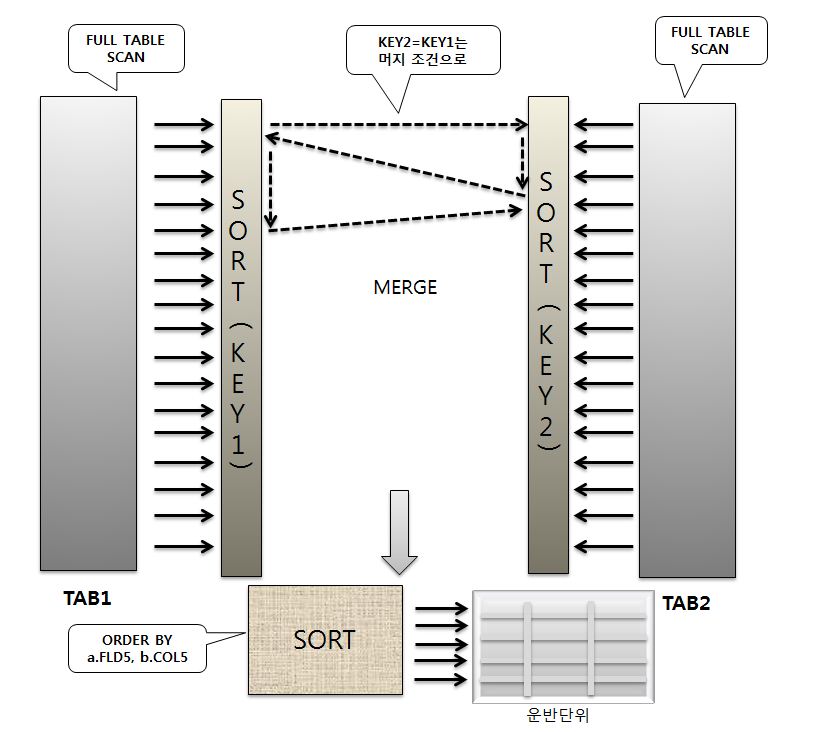 |
- 조인되는 양쪽에 모두 조건이 없으므로 각각의 테이블마다 전체 테이블을 스캔하여 연결고리가 되는 컬럼으로 정렬한 후 머지한다.
- 어차피 전체 테이블을 조인해야 한다면 랜덤으로 전체 테이블을 액세스하는 것보다 스캔방식으로 전체 테이블을 액세스하는 것이 당연 유리하다.
- 이와 같이 전체 테이블에 대한 Sort Merge 조인에서는 대량의 랜덤 액세스를 피할 수 있으므로 Nested Loops 조인에 비해 훨씬 더 유리해진다.
"구루비 데이터베이스 스터디모임" 에서 2011년에 "새로쓴 대용량 데이터베이스 솔루션1" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/4458
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.