새로쓴 대용량 데이터베이스솔루션 1 (2011년)
Nested Loops 조인
- Nested Loop 조인은 가장 전통적인 방법이면서, 보편적인 조인방식이다.
- 이 조인 방식이 그러한 역할을 하게 되는 가장 근복적인 이유는 먼저 엑서스한 결과를 다음의 엑세스에 상수값으로 제공해 줄 수 있다는데 있다.
- 하지만, 선행처리결과에서 범위를 적게 줄여 주었는데, 다음 처리할 집합에서 이것을 전혀 활용하지못한다면 이것은 전혀 효율적이지 않는다.
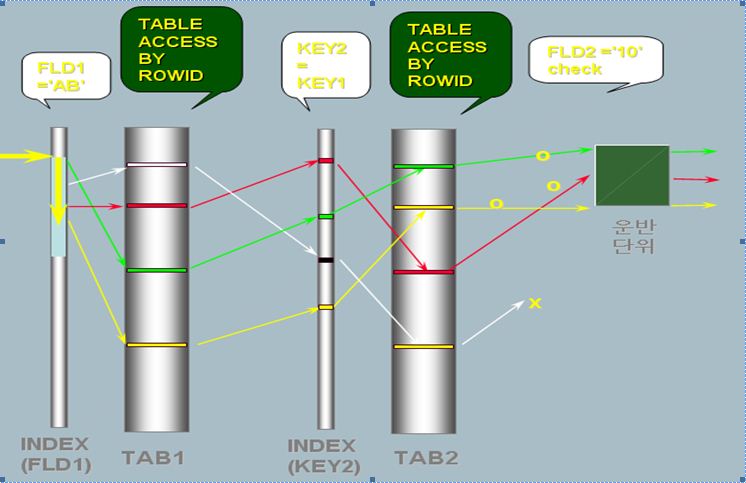 |
- Nested Loop 조인은 그림과 같이 절차로 수행하게 된다.
SELECT *
FROM TAB 1 A, TAB B
WHERE A.KEY1 = B.KEY2
AND A.FLD1 ='AB'
AND B.FLD2 ='10'
Nested Loops 조인의 특징
- 순차적, 선행적, 종속적, 랜덤 액세스, 선택적, 연결고리상태, 방향성, 부분범위처리가능, 체크조건의 영향력
Nested Loops 조인의 특징 및 적용기준
- 부분범위처리를 하는 경우에 유리해진다.(부분범위처리가능)
- 조인되는 어느 한족이 상대방 테이블에서 제공한 결과를 받아야만 처리범위를 줄일수 있는 상황이라면 Nested Loop 조인방식을 선택해야한다.(순차적, 선행적, 종속적)
- 주로 처리량이 적은 경우 라면 대개 Nested Loop 방식이 가장 무난하다.(랜덤 액세스)
- Nested Loop 방식은 연결고리의 인덱스를 이용하기 때문에 연결고리의 상태에 따라 매우 큰 차이가 발생한다(선택적, 연결고리 상태, 방향성)
- 먼저 수행한 집합의 처리범위의 크기와 얼마나 많은 처리 범위를 미리 줄여 줄 수 있느냐가 수행속도에 많은 영향을 미친다.(순차적,선행적)
- 부분범위처리를 하는 경우에는 운반단위의 크기가 수행속도에 상당항 영향을 미칠 수 있다.(부분범위처리)
- 선행 테이블의 처리 범위가 많거나 연결 테이블의 랜덤 엑세스의 양이 아주 많다면 Sort Merge 조인이나 해쉬조인을 검토해야 한다.(체크조건의 영향력)
Nested Loops 조인의 조인의 순서결정
- Nested Loop 은 먼저 수행되는 결과가 연결할 범위에 절대적인 영향을 미치기 때문에 어떤 순서로 선행조건이 수행되었는가가 중요하다.
SELECT ........
FROM TAB1 X, TAB2 Y, TAB3 Z
WHERE X.A1 = Y.B1
AND Z.C1 = Y.B2
AND Z.A2 = '10'
AND Y.B2 LIKE 'AB%';
| no | 순서 | ACCESS PATH |
|---|---|---|
| 1 | TAB1 TAB2 TAB3 | A2 ='10' B1 = A1 AND B2 LIKE 'AB%' C1 = B2 |
| 2 | TAB2 TAB3 TAB1 | B2 LIKE 'AB%' C1 = B2 A1 = B1 AND A2 ='10' |
| 3 | TAB3 TAB2 TAB1 | FULL TABLE SCAN B2 = C1 AND B2 LIE 'AB%' A1 = B1 AND A2 ='10' |
- 데이터 모델의 릴레이션쉽에 따라 조인의 성공률은 달라진다.
- 여기서 성공률이란 조인되는 집합이 자식 쪽이어서 1'쪽의 집합을 'M' 집합으로 증가시킨 다는 것을 표현한 말이다.
- 집합이 증가할수록 다음에 조인할 대상이 증가하는 것은 당연하므로 조인의 순서를
- 결정할 때 가능하다면 'M' 집합은 나중에 처리될수록 좋다. 물론 항상 그렇다는 것은아니다.
- 여기서 '가능하다면'이라는 말의 진정한 의미는 '자신의 처리범위를 줄여줄 수 있는 다른 집합이 먼저 엑세스 된후'
- 라는 의미와 자신이 먼저 처리범위를 줄여줄 수 있다면 그들보다 먼저 라는 의미가 함께 포함된것이다.
SELECT .....
FROM ITEM_MST M , ITEM_MOV V , VENDOR A, DEPT D
WHERE M.ITEM_CD = V.ITEM_CD
AND A.VENTOR = V.MANUFACTURE
AND D.DEPTNO = V.ACT_DEPT
AND M.CATEGORY = :B1
AND M.PMA LIKE :B2
AND V.PATERN = :B3
AND V.MOV_DATE BETWEEN :B4 AND :B5
AND D.LOCATION = :B6
위의 SQL은 ITEM_MST 와 ITEM_MOV가 1:M의 관계를 가지며 , ITEM_MOV에 VENDOR 와 DEPT가 '1'쪽 집합으로 연결된걸 알수있다.
 |
- 이 조인은 ITEM_MST -> ITEM_MOV -> VENDOR -> DEPT 순으로 수행되고있다.
(1) 인덱스를 스캔한 로우 수가 9621 인데 테이블을 액세스한 숫자는 4253이다.
- 인덱스를 스캔한 개수보다 테이블을 액세스한 숫자가 적다는 것은 인덱스 내부에서 체크하여 걸러졌다는걸 의미한다.
- ITEM_M_IDX1 인덱스에는 주어진 조건인 CATEGORY와 PMA 사이에 또 다른 컬럼이 존재하고 있었기 때문에 CATEGORY의 처리 범위인 9620개를 스캔하여 PMA 조건을 체크하니 4253개가 되었다는 것이다.
(2) 선행처리되는 ITEM_MST의 4253 개에 대해 M쪽 집합인 ITEM_MOV가 기본키를 이용해 연결을 하고있다.
- 약 1:57 비율로 연결이 되어 인덱스를 스캔한 숫자는 243209가 되었다.
- 그러나 테이블을 액세스 한 것이 그 보다 적은 83212이었다는 것은 조건을 받은 PATTERN이나 MOV_DATE중 하나의 기본키에 포함되어 있기는 하지만 그 사이에 다른 컬럼이 존재하고 있어 인덱스 내에 체크 되었음을 알 수 있다.
- 이렇게 조인한 결과는 (A)에 나타나는데 4218로 크게 감소한 것을 발견할 수 있다.
(3) 이제 상수값이 된 ITEM_MOV의 MANUFACTURE를 이용해 VENDOR 테이블을 연결하고 있다.
- 물론 기본키로 연결하기 때문에 나타난 숫자는 인덱스, 테이블 스캔 모두 4218이다.
- 이것은 곧 이 연결을 통해서 아무것도 줄여 주지 못했음을 의미한다.
(4) 마찬가지 방법으로 DEPT를 연결하였다. 그러나 (B)를 보면 조인에 최종적으로 성공한 것은
- 124개에 불과하다는 것을 알 수 있다. 이것은 바로 DEPT에 부여한 조건인 LOCATION으로 인한 것임을 쉽게 알 수 있다.
- 부분 처리가 완료된 후에 버리게 되었다는것은 비효율을 발생한 것은 틀림없다.
- 위 실행계획을 분석한 결과 문제점이 발견된걸 확인할수있다.
- ITEM_MOV의 MOV_DATE와 DEPT의 LOCATION 이었다. VENDOR는 전혀 범위를 줄여주지 못한것도 알수있다.
- 그렇다면 제일많은 데이터를 가진 ITEM_MOV 테이블을 가장 먼저 최소 범위를 만드는게 중요하다.
- MOV_DATE와 LOCATION이 :B6이 가진 DEPTNO 가 협력해서 처리할 범위를 최소화 시켜주는것이다.
- VENDOR는 처리범위를 줄여주지못하기 때문에 제일 나중에 조인되어야한다.
- 가장유리한 처리순서는 DEPT->ITEM_MOV->ITEM_MST->VENDOR 순이다.
- 많은범위 처리를 줄여주었던 DEPT 의 LOCATION이 젤먼저 범위를 줄여줘야지만 가장 먼저 엑세스 하여 해당 DEPTNO만 ITEM_MOV만 제공하여야 한다.
- 이때 가장 이상적인 인덱스 구조는 'ACT_DEPT+PATTERN+MOV_DATE' 이다.
- ITEM_MST가 세번째로 연결되어야 하는 이유는 여기서도 일부분 범위가 줄어들기 때문이다.
- 이 조인은 OTEM_CD 로만 생성된 기본키로 'UNIQUE_SCAN'을 하게 되므로 연결이 된 후에 나머지 조건인 CATEGORY와 PMA를 체크할수 밖에없다.
- 만약에 ITEM_MST의 조건인 CATEGORY, PMA 조인인덱스로 구성되어있다면 최적의 조인이 수행될것이다.
- 가령, 'ACT_DEPT+PATTERN+MOV_DATE'로 인덱스를 구성하지못하고 PATTERN+MOV_DATE로 된 인덱스를 사용할 수 밖에없다면,
- ITEM_MOV->DEPT->ITEM_MST->VENDOR 순으로 조인되는게 가장 유리하다.
조인의 순서를 결정하기 위한 구체적인 방법에 대해서 알아보도록 하겠다.
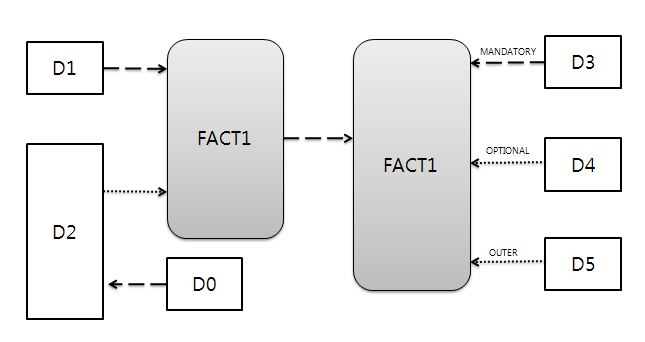 |
- 대부분의 조인쿼리는 몇 개의 트랜잭션 데이터가 들어가 있는 일종의 팩트 테이블이 존재한다,.
- 개념적으로는 하나의 집합이지만 정규화로 인해 이러한 모양이 될 수 있다.
- 그들의 주변에는 여러 개의 참조 모델들이 관계를 맺게 된다.
- 이러한 참조 모델들은 필수적(MANDATORY)관게를 가지거나, 선택적(OPTIONAL) 관계를 가지게 되며, 그 중에서는 아우터 조인으로 연결되기도 한다.
- 경우에 따라 D0 처럼 몇단계 걸친 관계의 조인도 발생한다.
- 조인을 하는경우 가장먼저 해야 할일은 조인하는 집합중에서 제일 하위 집합을 찾아내는일이다.
- 그림에서는 FACT2 테이블인걸 확인할수있다.
- 이테이블 기준으로 또다른 팩트 테이블이 FACT1을 찾을수가 있다.
- FACT1 테이블의 자기부여 상수조건은 D1, D2, D0
- FACT2 테이블의 자기부여 상수조건은 D3, D4, D5 인데 D5는 OUTER 조인이므로 제외한다.
- 이유는 아우터 조인은 제공자 역할을 할 수 없기 때문이다.
- 이런식으로 확보된 조건을 확인하여 처리범위를 많이 줄일수 있는지 비교해본뒤 애매한 경우 SROT MERGE 조인이나 해쉬조인으로 수행하는 경우가 많다.
- 우열을 가려졌으면 각 테이블이 보유한 인덱스 구조를 참조하여 다시한번 평가한다.
- 아무리 많은 조건이 걸려있어도 인덱스에 결합 되지 않았다면 인덱스 머지를 하지 않고서는 그중 하나만 선택되고 나머지는 체크 조건만 역할 한다.
- WHERE 절에 사용된 조건들은 어떤 수단으로 액세스를 했든지 소량의 집합이 된다면 선행되어야 할 이유는 충분히 존재한다.
- 그것은 다음 선행되는 처리범위를 줄여주기 때문이다.
- 또한, 자신은 비록 처리범위를 줄이지 못했지만 그 결과가 다른 조인에 좋은 영향을 미칠 수 있다면 선행처리 될수 있도록 한다.
- 집합을 증가 시키는 'M'쪽 집합과 조인이 남아 있다면 일단 그 집합을 조인하기 전에 남아 있는 연결 가능한 디멘전 테이블과 조인을 우선적으로 검토 하는 것이 좋다.
- 그 중 자신의 범위를 줄여줄수 있는 조건이 있다면 보다 많은 양을 줄일수 있는 것부터 조인을 하고, 아우터 조인은 마지막으로 보낸다.
- 여기까지 순서가 결정되었다면 'M'쪽 집합과 조인을 한다.
- 가능한 체크조건을 활용하여 조금이라도 줄여 줄 수 있는 것들부터 조인을 실시한다.
- 지금까지 처리된 집합의 결과를 조인하고자 하는 집합에 결과를 제공했을 때 그것을 받는것이 훨씬 유리하다면 NESTED LOOP 아니면, SORT MERGE나 해쉬 조인으로 유도해야한다.
- 최적의 처리경로를 알고 있어도 실행계획을 그렇게 나타나지 않는 경우가 존재한다.
- 그런경우에는 적절한 힌트나 인라인류를 잘활용 하는 방법이있다.
- 그래도 안되면 특정 컬럼의 인덱스 사용 억제를 활용하라!
- 그것도 또 안되면 ROWNUM을 삽입하여 특정 인라인뷰가 먼저 수행되도록 하는 등 갖가지 수단과 방법을 동원하라.
"구루비 데이터베이스 스터디모임" 에서 2011년에 "새로쓴 대용량 데이터베이스 솔루션1" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/4457
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.