오라클 성능 고도화 원리와 해법 II (2012년)
(7) 점이력 조회
- 데이터 변경이 발생할 때마다 변경일자와 함께 새로운 이력 레코드를 쌓는 방식을 점이력이라고 함.
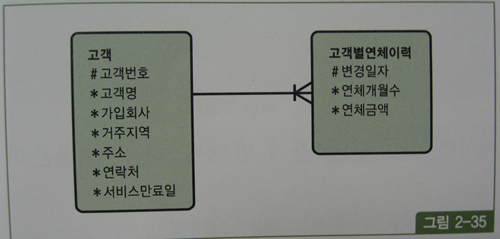 |
- 점이력 모델에서 이력을 조회할 때 흔히 아래와 같이 서브쿼리를 이용함
- 찾고자 하는 시점(서비스만료일) 보다 앞선 변경일자 중 가장 마지막 레코드를 찾는 것
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ no_unnest */ max(변경일자)
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일);
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 60 | 332 (0)| 00:00:04 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 16 | 960 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력_IDX01 2 | | 2 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 13 | | |
| 7 | FIRST ROW | | 5039 | 65507 | 3 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN (MIN/MAX)| 고객별연체이력_IDX01 5039 | 65507 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
- 서브쿼리 내에서 서비스만료일보다 작은 레코드를 모두 스캔하지 않고 오라클이 인덱스를 거꾸로 스캔하면서 가장 큰 값 하나만을 찾는 방식
- (7번재 라인 First row, 8번째 라인 min/max, 오라클8 버전에서 구현)
- 서브쿼리를 아래와 같이 바꿔줄 수 있지만 실제 수행해 보면 서브쿼리 내에서 액세스되는 인덱스 루트 블록에 대한 버퍼 Pinning효과가 사라져 블록 I/O가 더 많이 발생
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ index_desc(b 고객별연체이력_IDX01 */ 변경일자
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1);
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 60 | 332 (0)| 00:00:04 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 16 | 960 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 2 | | 2 (0)| 00:00:01 |
|* 6 | COUNT STOPKEY | | | | | |
|* 7 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 2 | 26 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
- 고객별연체이력_idx 인덱스를 두 번 액세스하는 비효율은 피할 수 없음
Index_desc 힌트와 rownum <=1 조건 사용시, 주의사항
- 인덱스 구성이 변경되면 쿼리 결과가 틀리게 될 수 있음을 반드시 기억 해야함
- first row(min/max) 알고리즘이 작동할 때는 반드시 min/max 함수를 사용하는 것이 올바른 선택
- 낮은 성능 때문에 어쩔수 없이 Index(또는 index_desc) + rownum조건을 써야만 하는 경우는
- 프로그램 목록을 관리했다가 인덱스 구성 변경시 확인하는 프로세스를 반드시 거쳐야함.
- 참고로, min 또는 max 함수 내에서 컬럼을 가공하면 first row 알고리즘이 작동하지 않는다.
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ no_unnest */ substr(max(변경일자 || 연체개월수), 9)
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일);
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 60 | 3836 (1)| 00:00:47 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 16 | 960 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 2 | | 2 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 16 | | |
| 7 | TABLE ACCESS BY INDEX ROWID| 고객별연체이력| 5039 | 80624 | 38 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN | 고객별연체이력_IDX01| 907 | | 6 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
- 스칼라 서브쿼리도 아래와 같이 max함수 사용하고 싶지만 first row 알고리즘이 작동하지 않아 부득이하게 index_desc힌트와 ronum 조건을 사용한 경우
select .....
,(selct substr(max(변경일자 || 연체금액), 9) from ...)
from 고객 a where .....
- 스칼라 서브쿼리로 변환하면 인덱스를 두번 액세스하지 않아도 되기 때문에 I/O를 그만큼 줄일 수 있음
- 여기서도 인덱스 루트 블록에 대한 버퍼 Pinning 효과는 사라진 것(10번 액세스하면서 30개 블록 I/O발생, 인덱스 height = 3)
select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ 연체금액
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1) 연체금액
from 고객 a
where 가입회사 = 'C70';
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 430 | 2 (0)| 00:00:01 |
|* 1 | COUNT STOPKEY | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 2 | 34 | 4 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN DESCENDING| 고객별연체이력_IDX01| 907 | | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
- 고객별연체이력 테이블로부터 연체금액 하나만 읽기 때문에 스칼라 서브쿼리로 변경하기가 수월했다
- 두개이상 컬럼을 읽어야 한다면 스칼라 서브쿼리 내에서 필요한 컬럼 문자열을 연결하고, 메인쿼리에서 substr함수로 잘라쓰는 방법을 사용해야 한다.
select 고객명, 거주지역, 주소, 연락처
, to_number(substr(연체, 3)) 연체금액
, to_number(substr(연체, 1, 2)) 연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */
lpad(연체개월수, 2) || 연체금액
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일
and rownum <= 1) 연체
from 고객 a
where 가입회사 = 'C70'
);
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 700 | 2 (0)| 00:00:01 |
| 1 | VIEW | | 10 | 700 | 2 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | 고객_IDX0| 10 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
- 이력 테이블에서 읽어야 할 컬럼 개수가 많다면 일일이 문자열로 연결하는 작업은 여간 번거롭지 않다.
- 스칼라 서브쿼리에서 rowid값만 취하고 고객별연체이력을 한번더 조인하는 방법을 생각해볼수 있다.
select /*+ ordered use_nl(b) rowid(b) */ a.*, b.연체금액, b.연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ rowid rid
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1) rid
from 고객 a
where 가입회사 = 'C70') a, 고객별연체이력 b
where b.rowid = a.rid;
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100K| 7381K| 12 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 100K| 7381K| 12 (0)| 00:00:01 |
| 2 | VIEW | | 10 | 560 | 2 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX0| 10 | | 1 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY USER ROWID | 고객별연체별이력 | 10079 | 187K| 1 (0)| 00:00:01 | --
------------------------------------------------------------------------------------------
- 고객별연체이력 테이블과 조인을 두 번 했지만 실행계획상 으로는 조인을 한 번만 한 것과 일량이 같다.
- 스칼라 서브쿼리 수행부분이 'VIEW'에 감춰져 보이지 않지만, 인덱스 이외의 컬럼을 참조하지 않았으므로 인덱스만 읽었을것이다.
- 거기서 얻은 rowid값으로 바로 테이블을 엑세스(Table Access by User ROWID)하기 때문에
- 일반적인 NL조인과 같은 프로세스(Outer 인덱스 -> Outer 테이블 -> Inner인덱스 -> Inner테이블)로 진행된다.
- 스칼라 서브쿼리를 이용하지 않고 아래와 같이 SQL을 구사해도 같은 방식으로 처리.
select /*+ ordered use_nl(b) rowid(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.rowid = (select /*+ index(c 고객별연체이력_idx01) */ rowid
from 고객별연체이력 c
where c.고객번호 = a.고객번호
and c.변경일자 <= a.서비스만료일
and rownum <= 1);
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 957 | 59334 | 312 (0)| 00:00:04 |
| 1 | NESTED LOOPS | | 9574K| 566M| 12 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 430 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY USER ROWID | 고객별연체이력| 1007K| 18M| 1 (0)| 00:00:01 |
|* 5 | COUNT STOPKEY | | | | | |
|* 6 | INDEX RANGE SCAN | 고객별연체이력| 2 | 38 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
- 고객(a)에서 읽은 고객번호로 서브쿼리 쪽 고객별연체이력©과 조인하고, 거기서 얻으 rowid값으로 고객별연체이력(b)을 곧바로 액세스한다. a와 b간에 따로 조인문을 기술하는 것은 불필요하다.
- 고객별연체이력을 두 번 사용했지만 실행계획 상으로는 한 번만 조인하면서 일반적인 NL조인과 같은 프로세스
- (Outer인덱스 -> Otuer 테이블 -> Inner인덱스 -> Inner테이블)로 진행되는 것에 주목하기 바란다.
정해진 시점 기준으로 조회
- 앞에서는 가입회사 = 'C70'에 속하는 고객 수가 10명.
- 만약 가입회사별 고객수가 많아지면 서브쿼리 수행횟수가 늘어나 Random I/O부하도 심해질 것이다.
- 가입회사 조건절없이 모든 고객을 대상으로 이력을 조회한다면 ?
- 고객 테이블로부터 읽히는 미지의 시점(서비스 만료일)을 기준으로 이력을 조회하는 경우이기 때문에 위와 같이 Random 액세스 위주의 서브쿼리를 쓸수 밖에 없다.
- 정해진 시점을 기준으로 조회하는 경우라면 서브쿼리를 쓰지 않음으로써 Random 액세스 부하를 줄일 방법들이 몇가지 생긴다.
select /*+ full(a) full(b) full(c) use_hash(a b c) no_merge(b) */
a.고객명, a.거주지역, a.주소, a.연락처, c.연체금액, c.연체개월수
from 고객 a
,(select 고객번호, max(변경일자) 변경일자
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')
group by 고객번호) b, 고객별연체이력 c
where b.고객번호 = a.고객번호
and c.고객번호 = b.고객번호
and c.변경일자 = b.변경일자;
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 680 | 1603 (4)| 00:00:20 |
|* 1 | HASH JOIN | | 10 | 680 | 1603 (4)| 00:00:20 |
|* 2 | HASH JOIN | | 10 | 490 | 809 (5)| 00:00:10 |
| 3 | TABLE ACCESS FULL | 고객 | 10 | 300 | 3 (0)| 00:00:01 |
| 4 | VIEW | | 10 | 190 | 805 (4)| 00:00:10 |
| 5 | HASH GROUP BY | | 10 | 130 | 805 (4)| 00:00:10 |
|* 6 | TABLE ACCESS FULL| 고객별연| 9881 | 125K| 804 (4)| 00:00:10 |
| 7 | TABLE ACCESS FULL | 고객별연| 1007K| 18M| 788 (2)| 00:00:10 |
---------------------------------------------------------------------------------
- 가장 단순하게 작성된 위 쿼리는 고객별연체이력 테이블을 두번 Full Scan하는 비효율을 가짐
select a.고객명, a.거주지역, a.주소, a.연락처
, to_number(substr(연체, 11)) 연체금액
, to_number(substr(연체, 9, 2)) 연체개월수
from 고객 a
,(select 고객번호, max(변경일자 || lpad(연체개월수, 2) || 연체금액 ) 연체
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')
group by 고객번호) b
where b.고객번호 = a.고객번호;
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 251 | 15311 | 395 (1)| 00:00:05 |
| 1 | HASH GROUP BY | | 251 | 15311 | 395 (1)| 00:00:05 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객별연체이력| 988 | 18772 | 39 (0)| 00:00:01 |
| 3 | NESTED LOOPS | | 9881 | 588K| 393 (0)| 00:00:05 |
| 4 | TABLE ACCESS FULL | 고객 | 10 | 420 | 3 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력| 988 | | 5 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
- 이력 테이블에서 읽어야 할 컬럼 개수가 많다면 위와 같이 일일이 문자열로 연결하는 작업은 여간 번거롭지 않음
- 그때는 아래와 같이 분석함수를 이용하는 것이 편하고, 수행 속도 면에서도 전혀 불리하지 않음
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a
,(select 고객번호, 연체금액, 연체개월수, 변경일자
, row_number() over (partition by 고객번호 order by 변경일자 desc) no
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')) b
where b.고객번호 = a.고객번호
and b.no = 1;
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9881 | 810K| | 869 (4)| 00:00:11 |
|* 1 | HASH JOIN | | 9881 | 810K| | 869 (4)| 00:00:11 |
| 2 | TABLE ACCESS FULL | 고객 | 10 | 300 | | 3 (0)| 00:00:01 |
|* 3 | VIEW | | 9881 | 521K| | 865 (4)| 00:00:11 |
|* 4 | WINDOW SORT PUSHED RANK| | 9881 | 183K| 632K| 865 (4)| 00:00:11 |
|* 5 | TABLE ACCESS FULL | 고객별연| 9881 | 183K| | 804 (4)| 00:00:10 |
---------------------------------------------------------------------------------------------
- 아래와 같이 max함수를 이용할 수도 있지만 방금처럼 row_number를 이용하는 것이 더 효과적인데, 자세한 원리는 5장 6절에서 설명.
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a
,(select 고객번호, 연체금액, 연체개월수, 변경일자
, max(변경일자) over (partition by 고객번호) max_dt
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')) b
where b.고객번호 = a.고객번호
and b.변경일자 = b.max_dt;
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9881 | 781K| | 869 (4)| 00:00:11 |
|* 1 | HASH JOIN | | 9881 | 781K| | 869 (4)| 00:00:11 |
| 2 | TABLE ACCESS FULL | 고객 | 10 | 300 | | 3 (0)| 00:00:01 |
|* 3 | VIEW | | 9881 | 492K| | 865 (4)| 00:00:11 |
| 4 | WINDOW SORT | | 9881 | 183K| 632K| 865 (4)| 00:00:11 |
|* 5 | TABLE ACCESS FULL| 고객별연| 9881 | 183K| | 804 (4)| 00:00:10 |
----------------------------------------------------------------------------------------
"구루비 데이터베이스 스터디모임" 에서 2012년에 "오라클 성능 고도화 원리와 해법 II " 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/4437
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.