오라클 성능 고도화 원리와 해법 II (2012년)
(5) 최종 출력 건에 대해서만 조인하기
- 화면 페이지 처리시 흔히 사용되는 방식이다.
SELECT *
FROM (
SELECT ROWNUM NO, 등록일자, 번호, 제목
, 회원명, 게시판유형명, 질문유형명, COUNT(*) OVER() CNT
FROM(
SELECT A.등록일자, A.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명
FROM 게시판 A, 회원 B, 게시판유형 C, 질문유형 D
WHERE A.게시판유형 = :TYPE
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
ORDER BY A.등록일자 DESC, A.질문유형, A.번호
)
WHERE ROWNUM <= 31
)
WHERE NO BETWEEN 21 AND 30
- 전체 게시판 데이터는 수백만 건이고, 특정 게시판 유형(게시판유형 = :TYPE)에 속하는 데이터는 평균 10만 건에 이른다.
- 게다가 회원, 게시판유형, 질문유형 3개 테이블과 조인까지 수행하므로 성능이 좋을리 없다.
- 인덱스 구성은 아래와 같아서 소트 오퍼레이션이 불가피하다.
- >> 게시판_X01 : 게시판유형 + 등록일자 DESC + 번호
- 실행계획을 보면(교재참고 p.313), 10만 건을 읽어 나머지 세 테이블과의 조인을 모두 완료한 후에 소트 단계에서 stopkey가 작동(id=5)하고 있다.
Execution Plan
--------------------------------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 VIEW
2 1 WINDOW (BUFFER)
3 2 COUNT (STOPKEY)
4 3 VIEW
5 4 SORT (ORDER BY STOPKEY)
6 5 NESTED LOOPS
7 6 NESTED LOOPS
8 7 NESTED LOOPS
9 8 TABLE ACCESS (BY LOCAL INDEX ROWID) OF '게시판' (TABLE)
10 9 INDEX (RANGE SCAN) OF '게시판_X01' (INDEX (UNIQUE))
11 10 TABLE ACCESS (BY INDEX ROWID) OF '회원' (TABLE)
12 11 INDEX (UNIQUE SCAN) OF '회원_PK' (INDEX (UNIQUE))
13 7 TABLE ACCESS (BY INDEX ROWID) OF '게시판유형' (TABLE)
14 13 INDEX (UNIQUE SCAN) OF '게시판유형_PK' (INDEX (UNIQUE))
15 6 TABLE ACCESS (BY INDEX ROWID) OF '질문유형' (TABLE)
16 15 INDEX (UNIQUE SCAN) OF '질문유형_PK' (INDEX (UNIQUE))
- 튜닝을 위해 게시판_X01 인덱스에 질문유형 컬럼을 추가하자.
- 인덱스 컬럼 순서를 바꾸는 결정을 하기는 쉽지 않지만 뒤쪽에 추가하는 것은 그다지 어렵지 않다.
- >> 게시판_X01 : 게시판유형 + 등록일자 DESC + 번호 + 질문유형
- 위처럼 인덱스를 구성했다면 게시판 테이블로부터 '게시판유형 = :TYPE' 조건에 해당하는 레코드를 찾는 작업은 인덱스 내에서 해결 가능하다.
- 아래처럼 인덱스만 읽도록 쿼리를 작성
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형 = :TYPE
ORDER BY 등록일자 DESC, 질문유형, 번호
- 읽은 레코드를 정렬하는 작업은 피할 수 없지만, 인덱스 블록만 읽으면 되기 때문에 이전보다 훨씬 빠르게 수행될 것이다.
- 다른 세 개 테이블과의 조인 컬럼, 그리고 select-list에서 참조되는 컬럼을 어떻게 읽어올 것인지가 문제인데, 이들 컬럼은 페이지 처리가 모두 완료되 최종 결과집합으로 확정된 10건에 대해서만 액세스하면 된다.
- 그럴 목적으로 인덱스를 스캔할 때 rowid 값을 같이 읽어온 것이다. 최종적으로 완성된 쿼리는 아래와 같다.
SELECT /*+ ORDERED USE_NL(A) USE_NL(B) USE_NL(C) USE_NL(D) ROWID(A) */
A.등록일자, B.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명, X.CNT
FROM (
SELECT RID, ROWNUM NO, COUNT(*) OVER() CNT
FROM (
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형 = :TYPE
ORDER BY 등록일자 DESC, 질문유형, 번호
)
WHERE ROWNUM <= 31
) X, 게시판 A, 회원 B, 게시판유형 C, 질문유형 D
WHERE X.NO BETWEEN 21 AND 30
AND A.ROWID = X.RID
AND B.회원번호 = A.작성자번호
AND C.게시판유형 = A.게시판유형
AND D.질문유형 = A.질문유형
Execution Plan
---------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 NESTED LOOPS
2 1 NESTED LOOPS
3 2 NESTED LOOPS
4 3 NESTED LOOPS
5 4 VIEW
6 5 COUNT (STOPKEY)
7 6 VIEW
8 7 SORT (ORDER BY STOPKEY)
9 8 INDEX (RANGE SCAN) OF '게시판_X01' (INDEX (UNIQUE))
10 4 TABLE ACCESS (BY USER ROWID) OF '게시판' (TABLE) -- BY USER ROWID
11 3 TABLE ACCESS (BY INDEX ROWID) OF '회원' (TABLE)
12 11 INDEX (UNIQUE SCAN) OF '회원_PK' (INDEX (UNIQUE))
13 2 TABLE ACCESS (BY INDEX ROWID) OF '게시판유형' (TABLE)
14 13 INDEX (UNIQUE SCAN) OF '게시판유형_PK' (INDEX (UNIQUE))
15 1 TABLE ACCESS (BY INDEX ROWID) OF '질문유형' (TABLE)
16 15 INDEX (UNIQUE SCAN) OF '질문유형_PK' (INDEX (UNIQUE))
- 게시판 테이블을 두 번 읽도록 쿼리를 작성했지만 인라인 뷰 내에서는 인덱스만 읽도록 했고, 두 번째 게시판 테이블(A)을 액세스할 때는 앞서 읽은 rowid 값으로 직접 액세스하기 때문에 인덱스를 경유해 한 번만 테이블을 액세스하는 것과 같은 일량이다.
- 실행계획에 'TABLE ACCESS BY INDEX ROWID'가 아니라 'TABLE ACCESS BY USER ROWID'로 표시된 것에 주목하자.
- 조인 컬럼이 null 허용일때는 결과가 달라질 수 있다.
- 회원, 게시판유형, 질문유형 테이블과의 조인 컬럼인 작성자번호, 게시판유형, 질문유형이 null 허용 컬럼이 존재하는지 확인해 봐야 한다.
- 업무적으로 null 값이 허용되지 않는데도 컬럼에 not null 제약을 설정하지 않는 경우가 매우 흔하기 때문이다.
- 그리고, 이들 컬럼이 null 값이라고 해서 게시판 출력 리스트에서 제외되는 것이 업무적으로 맞는지 확인해 볼 필요가 있다.
- 아마도 Outer 조인을 했어야 옳은데, 개발자가 간과한 경우일 수 있다.
- 위 쿼리에 아래처럼 Outer 기호( + )만 붙여주면 된다.
WHERE X.NO BETWEEN 21 AND 30
AND A.ROWID = X.RID
AND B.회원번호(+) = A.작성자번호
AND C.게시판유형(+) = A.게시판유형
AND D.질문유형(+) = A.질문유형
반정규화는 성능을 위한 최후의 수단
- 정규화된 모델로는 제대로된 성능을 내기 어려울 때만 반정규화를 단행하는 것이 관계형 데이터베이스를 구현하는 정석이다.
- 그럼에도 성능이 좋지 않을 것을 예단하고 논리 데이터 모델링 단계에서 미리 반정규화를 실시하는 설계자나 개발팀을 자주 본다.
 |
- 예를 들어, page. 317의 그림 2-27과 같은 업무연락 메시지 게시판을 구현하기 위한 데이터 모델을 열어보면 영락없이 그림 2-28처럼 발송메시지건수, 수신인수 같은 추출(derived)속성들이 설계되 있다.
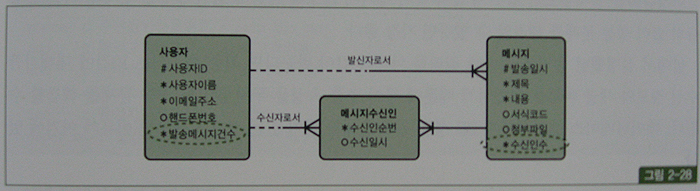 |
- page. 317의 그림2-27과 같은 업무를 아래와 같은 SQL로 개발했다면 수신확인자수와 수신대상자수를 세고 새글여부를 확인하는 스칼라 서브쿼리 때문에 성능 문제를 겪었을 것이고, 이를 해결하지 못하면 위의 그림과 같이 설계하기 마련이다.
SELECT ..
FROM (
SELECT ..
FROM (
SELECT a.발신인ID, a,발송일시, a.제목, b.사용자이름 AS 보낸이
, ( SELECT COUNT(수신일시) FROM 메시지수신인 ..) 수신확인자수
, ( SELECT COUNT(*) FROM 메시지수신인 ..) 수신대상자수
, ( CASE WHEN EXISTS ( SELECT 'x' FROM 메시지수신인
WHERE 발신자ID = a.발신자ID
AND 발송일시 = a.발송일시
AND 수신자ID = :로그인사용자ID
AND 수신일시 IS NULL ) THEN 'Y' END ) 새글여부
FROM 메시지 a, 사용자 b
ORDER BY a.발송일시 DESC
) a
WHERE rownum <= 10
)
WHERE no between 1 and 10;
- 위와 같은 추출 속성을 도입하면 메시지를 수신할 때마다 메시지 테이블의 수신인수를 갱신해주는 DML도 같이 작성해야 한다.
- 문제는 일상적이지 않은 업무로 데이터 정합성이 훼손될 수 있다는데 있다.
- 예를 들어 사용자가 탈퇴하면 메시지 수신인수도 일괄적으로 갱신해 주어야 하는데, 그런 처리를 실수로 빠뜨리기 쉽다.
- 반정규화를 실시했으면 업무 규칙 누락이 생기지 않도록 꼼꼼히 점검해야 한다.
- 최종 출력되는 10건에 대해서만 수신정보와 새글 여부를 확인하는 방식으로 쿼리 변경하여 성능 문제 해결
- (스칼라 서브쿼리를 맨 바깥의 SELECT LIST에서 처리함)
SELECT a.발신인ID, a,발송일시, a.제목, b.사용자이름 AS 보낸이
, ( SELECT COUNT(수신일시) || '/' || COUNT(*) FROM 메시지수신인 ..) 수신확인
, ( CASE WHEN EXISTS ( .. ) THEN 'Y' END ) 새글여부
FROM (
SELECT ROWNUM NO, ...
FROM ( SELECT 발신인ID, a,발송일시, a.제목 FROM 메시지 ORDER BY a.발송일시 DESC )
WHERE ROWNUM <= 30
) a, 사용자 b
WHERE NO BETWEEN 21 AND 30;
AND .........
"구루비 데이터베이스 스터디모임" 에서 2012년에 "오라클 성능 고도화 원리와 해법 II " 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/4435
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.