press x to close
-- 조인 선택도를 구하는 공식
Sel = 1 / max[(NDV(t1.c1), NDV(t2.c2)] *
((card t1 - # t1.c1 NULLS) / card t1) *
((card t2 - # t2.c2 NULLS) / card t2)
조인 선택도 =
((num_rows(t1) - num_nulls(t1.c1)) / num_rows(t1)) *
((num_rows(t2) - num_nulls(t2.c2)) / num_rows(t2)) *
greater(num_distinct(t1.c1), num_distinct(t2.c2))
-> user_tables.num_rows
-> user_tab_col_statistics.num_nulls
-> user_tab_col_statistics.num_distinct
-- 조인 카디널리티(Cardinality)를 구하는 공식
Card(Pj) = card(t1) * card(t2) * sel(Pj)
조인 카디널리티 =
조인 선택도 *
필터된 카디널리티(t1) * 필터된 카디널리티(t2)
--> 필터된 카디널리티 : 조인조건외의 다른 조건들을 각 테이블에 적용한 것.
-- (조인 조건중 일부가 필터 조건처럼 작용할 수 도 있다)
create table t1 AS
SELECT trunc(dbms_random.value(0, 25 )) filter,
trunc(dbms_random.value(0, 30 )) join1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 10000 ;
create table t2 AS
SELECT trunc(dbms_random.value(0, 50 )) filter,
trunc(dbms_random.value(0, 40 )) join1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 10000 ;
-- Collect statistics using dbms_stats here
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t1.filter = 1
AND t2.join1 = t1.join1
AND t2.filter = 1 ;
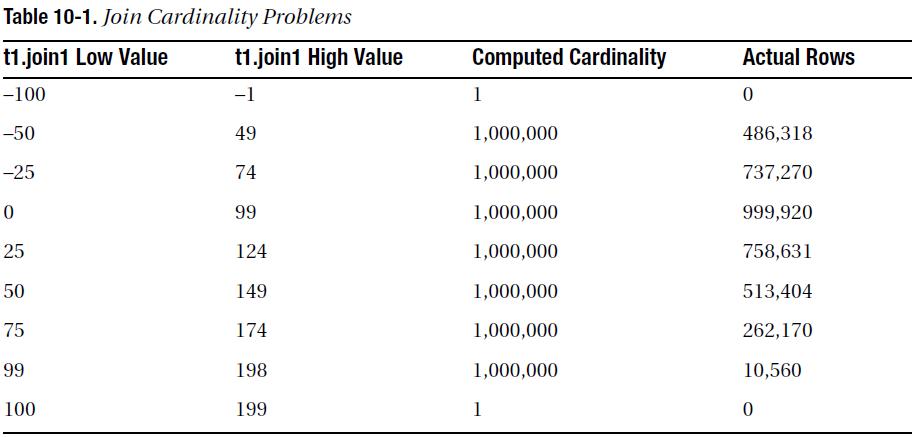
- 조인 카디널리티
Join Selectivity =
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(30, 40) = 1/40
Join Cardinality = 1/40 * (400 * 200) = 2000
- autotrace 결과
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=57 Card=2000 Bytes=68000)
1 0 HASH JOIN (Cost=57 Card=2000 Bytes=68000)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=200 Bytes=3400)
3 2 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=400 Bytes=6800)
update t1 set join1 = null
where mod(to_number(v1),20) = 0;
-- 500 rows updated
update t2 set join1 = null
where mod(to_number(v1),30) = 0;
-- 333 rows updated
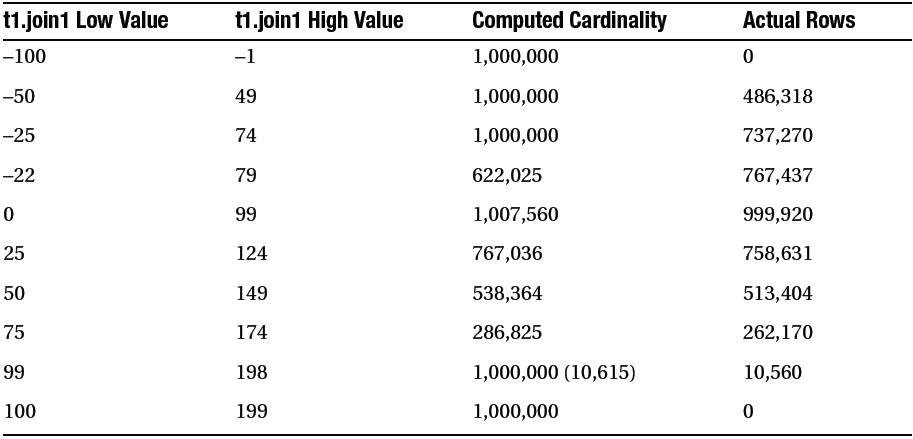
- 조인 카디널리티
Join Selectivity =
(10,000 - 500) / 10,000) *
(10,000 - 333) / 10,000) /
greater(30, 40) = 0.022959125
Join Cardinality = 400 * 200 * 0.022959125 = 1,836.73
- autotrace 결과
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=57 Card=1837 Bytes=62458)
1 0 HASH JOIN (Cost=57 Card=1837 Bytes=62458)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=200 Bytes=3400)
3 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=400 Bytes=6800)
update t1 set filter = null
where mod(to_number(v1),50) = 0;
-- 200 rows updated
update t2 set filter = null
where mod(to_number(v1),100) = 0;
-- 100 rows updated
- 필터조건(filter = 1) 컬럼에 NULL 값이 존재하므로 테이블별로 필터된 카디널리티만 다시 계산.
Adjusted (computed) Cardinality = Base Selectivity * (num_rows - num_nulls)
. For table t1 we have 1/25 * (10,000 . 200) = 392.
. For table t2 we have 1/50 * (10,000 . 100) = 198.
- 조인 카디널리티
Join Cardinality = 392 * 198 * 0.022959125 = 1,781.995
- autotrace 결과
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=57 Card=1782 Bytes=60588)
1 0 HASH JOIN (Cost=57 Card=1782 Bytes=60588)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=198 Bytes=3366)
3 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=392 Bytes=6664)
create table t1 AS
SELECT trunc(dbms_random.value(0, 100 )) filter,
trunc(dbms_random.value(0, 30 )) join1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 1000 ;
create table t2 AS
SELECT trunc(dbms_random.value(0, 100 )) filter,
trunc(dbms_random.value(0, 40 )) join1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 1000 ;
-- Collect statistics using dbms_stats here
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t2.join1 = t1.join1
-- and t1.filter = 1
AND t2.filter = 1 ;
Join Selectivity =
(1000 / 1000) * (1000 / 1000) / greater(30, 40) =
1/40 = 0.025
Join Cardinality =
Join Selectivity *
filtered cardinality(t1) * filtered cardinality(t2) =
0.025 * 10 * 1000 = 250
- autotrace 결과
Execution Plan (9.2.0.6 Filter on just T1)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=11 Card=250 Bytes=7750)
1 0 HASH JOIN (Cost=11 Card=250 Bytes=7750)
2 1 TABLE ACCESS (FULL) OF 'T1' (Cost=5 Card=10 Bytes=170)
3 1 TABLE ACCESS (FULL) OF 'T2' (Cost=5 Card=1000 Bytes=14000)
Execution Plan (9.2.0.6 Filter on just T2)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=11 Card=333 Bytes=10323)
1 0 HASH JOIN (Cost=11 Card=333 Bytes=10323)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=5 Card=10 Bytes=170)
3 1 TABLE ACCESS (FULL) OF 'T1' (Cost=5 Card=1000 Bytes=14000)
create table t1 AS
SELECT trunc(dbms_random.value(0, 30 )) join1,
trunc(dbms_random.value(0, 50 )) join2,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 10000 ;
create table t2 AS
SELECT trunc(dbms_random.value(0, 40 )) join1,
trunc(dbms_random.value(0, 40 )) join2,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 10000 ;
-- Collect statistics using dbms_stats here
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t2.join1 = t1.join1
AND t2.join2 = t1.join2 ;
- autotrace 결과
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=60 Card=50000 Bytes=1700000)
1 0 HASH JOIN (Cost=60 Card=50000 Bytes=1700000)
2 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=10000 Bytes=170000)
3 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=10000 Bytes=170000)
- 조인선택도
Join Selectivity =
{join1 bit} *
{join2 bit} =
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(30, 40) * -- uses the t2 selectivity (1/40)
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(50, 40) = -- uses the t1 selectivity (1/50)
1/40 * 1/50 = 1/2000
Execution Plan (10.1.0.4 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=60 Card=62500 Bytes=2125000)
1 0 HASH JOIN (Cost=60 Card=62500 Bytes=2125000)
2 1 TABLE ACCESS (FULL) OF 'T1' (TABLE) (Cost=28 Card=10000 Bytes=170000)
3 1 TABLE ACCESS (FULL) OF 'T2' (TABLE) (Cost=28 Card=10000 Bytes=170000)
- 조인선택도
62,500 = 100,000,000 * join selectivity.
Join selectivity = 62,500 / 100,000,000 = 1/1,600
Table: T1 Multi-column join key card: 1500.000000 (30 * 50)
Table: T2 Multi-column join key card: 1600.000000 (40 * 40)
Using multi-column join key sanity check for table T2
Revised join selectivity: 6.2500e-004 = 5.0000e-004 * (1/1600) * (1/5.0000e-004)
Join Card: 62500.00 = outer (10000.00) * inner (10000.00) * sel (6.2500e-004)
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t2.join1 != t1.join1 -- (30 / 40 values for num_distinct)
AND t2.join2 != t1.join2 -- (50 / 40 values for num_distinct)
;
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t1.join1 = 20 -- 30 distinct values
AND t2.join1 = t1.join1 -- 40 / 30 distinct values
AND t2.join2 = t1.join2 -- 40 / 50 distinct values
;
- t1.join1 = 20이 없을 경우
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=60 Card=50000 Bytes=1700000)
1 0 HASH JOIN (Cost=60 Card=50000 Bytes=1700000)
2 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=10000 Bytes=170000)
3 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=10000 Bytes=170000)
- 조건 추가했을경우
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=57 Card=1667 Bytes=56678)
1 0 HASH JOIN (Cost=57 Card=1667 Bytes=56678)
2 1 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=250 Bytes=4250)
3 1 TABLE ACCESS (FULL) OF 'T1' (Cost=28 Card=333 Bytes=5661)
- dbms_xplan
--------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1667 | 56678 | 57 |
|* 1 | HASH JOIN | | 1667 | 56678 | 57 |
|* 2 | TABLE ACCESS FULL | T2 | 250 | 4250 | 28 |
|* 3 | TABLE ACCESS FULL | T1 | 333 | 5661 | 28 |
--------------------------------------------------------------------
Predicate Information (identified by operation id):
1 - access("T2"."JOIN2"="T1"."JOIN2")
2 - filter("T2"."JOIN1"=20)
3 - filter("T1"."JOIN1"=20)
Join Selectivity =
((num_rows(t1) - num_nulls(t1.c1)) / num_rows(t1)) *
((num_rows(t2) - num_nulls(t2.c2)) / num_rows(t2)) /
greater(num_distinct(t1.c1), num_distinct(t2.c2))
Join Cardinality =
join selectivity *
filtered cardinality(t1) * filtered cardinality(t2)
Join Selectivity =
((10000 - 0)/ 10000) *
((10000 - 0)/ 10000) /
greater(40, 50) = -- t1.join2, t2.join2 (num_distinct)
1/50
Join Cardinality =
(1 / 50) *
10000/30 * 10000/40 = -- t1.join1 has 30 values, t2.join1 has 40
333 * 250 / 50 =
1,666.66
SELECT t1.v1,
t2.v1
FROM t1,
t2
WHERE t1.join1 = 20 -- 30 distinct values
AND t2.join1 = t1.join1 -- 40 / 30 distinct values
AND t2.join2 = t1.join2 -- 40 / 50 distinct values
AND t2.join1 = 20 -- 40 distinct values
;
- dbms_xplan
--------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
--------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 42 | 1428 | 57 |
|* 1 | HASH JOIN | | 42 | 1428 | 57 |
|* 2 | TABLE ACCESS FULL | T2 | 250 | 4250 | 28 |
|* 3 | TABLE ACCESS FULL | T1 | 333 | 5661 | 28 |
--------------------------------------------------------------------
Predicate Information (identified by operation id):
1 - access("T2"."JOIN1"="T1"."JOIN1" AND "T2"."JOIN2"="T1"."JOIN2")
2 - filter("T2"."JOIN1"=20)
3 - filter("T1"."JOIN1"=20)
- 9i
Join Selectivity =
{join1 bit} *
{join2 bit} =
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(30, 40) *
(10,000 - 0) / 10,000) *
(10,000 - 0) / 10,000) /
greater(50, 40) =
1/40 * 1/50 = 1/2000
Join Cardinality =
(1 / 2000) *
10000 / 30 * 10000 / 40 =
333 * 250 / 2000 =
41.625
- 10g
Join Cardinality =
(1 / 1600) *
10000 / 30 * 10000 / 40 =
333 * 250 / 2000 =
52.031
SELECT t1.v1,
t2.v1,
t3.v1
FROM t1,
t2,
t3
WHERE t2.join1 = t1.join1 -- 36 / 40 distinct values
AND t2.join2 = t1.join2 -- 38 / 40 distinct values
--
AND t3.join2 = t2.join2 -- 37 / 38 distinct values
AND t3.join3 = t2.join3 -- 39 / 42 distinct values
--
AND t3.join4 = t1.join4 -- 41 / 40 distinct values
;
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=109 Card=9551 Bytes=573060)
1 0 HASH JOIN (Cost=109 Card=9551 Bytes=573060)
2 1 TABLE ACCESS (FULL) OF 'T3' (Cost=28 Card=10000 Bytes=200000)
3 1 HASH JOIN (Cost=62 Card=62500 Bytes=2500000)
4 3 TABLE ACCESS (FULL) OF 'T1' (Cost=29 Card=10000 Bytes=200000)
5 3 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=10000 Bytes=200000)
Join Selectivity =
{join1 bit} *
{join2 bit} =
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater (36 , 40) *
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater (38 , 40) =
1/1600
Join Cardinality =
1 / 1600 *
10000 * 10000 =
62,500
- 62,500개의 로우를 갖는 중간집합을 생성.
Join Selectivity =
{join2 bit} *
{join3 bit} *
{join4 bit} =
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater( 37, 38) * -- greater( 37, 40)으로 대체해야 하지 않을까?
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater( 39, 42) *
((10000 - 0) / 10000) *
(10000 - 0) / 10000)) /
greater( 41, 40) =
1/65,436
Join Cardinality =
1 / 65436 *
62500 * 10000 =
9,551 (as required)
t2.join1 = t1.join1
and t2.join2 = t1.join2
--
and t3.join3 = t2.join3
--
and t3.join2 = t1.join2 -- was t3.join2 = t2.join2
and t3.join4 = t1.join4
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=109 Card=9074 Bytes=544440)
1 0 HASH JOIN (Cost=109 Card=9074 Bytes=544440)
2 1 TABLE ACCESS (FULL) OF 'T3' (Cost=28 Card=10000 Bytes=200000)
3 1 HASH JOIN (Cost=62 Card=62500 Bytes=2500000)
4 3 TABLE ACCESS (FULL) OF 'T1' (Cost=29 Card=10000 Bytes=200000)
5 3 TABLE ACCESS (FULL) OF 'T2' (Cost=28 Card=10000 Bytes=200000)
create table t1 AS
SELECT mod(rownum-1, 15) n1,
lpad(rownum, 10) v1,
rpad('x', 100) padding
FROM all_objects
WHERE rownum <= 150 ;
UPDATE t1
SET n1 = null
WHERE n1 = 0;
SELECT /*+ ordered */
t1.v1,
t2.v1,
t3.v1
FROM t1,
t2,
t3
WHERE t2.n1 = t1.n1
AND t3.n1 = t2.n1 ;
Execution Plan (9.2.0.6 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=8 Card=9000 Bytes=378000)
1 0 HASH JOIN (Cost=8 Card=9000 Bytes=378000)
2 1 TABLE ACCESS (FULL) OF 'T3' (Cost=2 Card=140 Bytes=1960)
3 1 HASH JOIN (Cost=5 Card=900 Bytes=25200)
4 3 TABLE ACCESS (FULL) OF 'T1' (Cost=2 Card=90 Bytes=1260)
5 3 TABLE ACCESS (FULL) OF 'T2' (Cost=2 Card=110 Bytes=1540)
Execution Plan (8.1.7.4 autotrace)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=5 Card=8250 Bytes=346500)
1 0 HASH JOIN (Cost=5 Card=8250 Bytes=346500)
2 1 TABLE ACCESS (FULL) OF 'T3' (Cost=1 Card=150 Bytes=2100)
3 1 HASH JOIN (Cost=3 Card=900 Bytes=25200)
4 3 TABLE ACCESS (FULL) OF 'T1' (Cost=1 Card=100 Bytes=1400)
5 3 TABLE ACCESS (FULL) OF 'T2' (Cost=1 Card=120 Bytes=1680)
t1.n1 is not null
t2.n1 is not null
t3.n1 is not null
- 8i
T1 to T2: the tables with 100 and 120 rows respectively:
Join Selectivity =
(100 - 10) / 100) *
(120 - 10) / 120) /
greater(9, 11) = 0.075
Join Cardinality =
0.075 * 100 * 120 = 900
Intermediate to T3: the table with 150 rows:
Join Selectivity =
(120 - 10) / 120) * -- the CBO uses the t2 figures at one end
(150 - 10) / 150) / -- of the join, and the t3 at the other.
greater(11, 14) =
0.0611111
Join Cardinality =
0.061111 * 900 * 150 =
8,250
- 9i
T1 to T2: the tables with 100 and 120 rows respectively:
Join Selectivity =
1 / greater(9, 11) =
0.09090909
Join Cardinality =
0.09090909 * 90 * 110 =
900
Intermediate to T3: the table with 150 rows:
Join Selectivity =
1 / greater(11, 14) =
0.0714285
Join Cardinality =
0.0714285 * 900 * 140 =
9,000 (as required)
- 강좌 URL : http://www.gurubee.net/lecture/3983
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.