press x to close
SQL> create table t1 ( date_ord date constraint t1_dto_nn not null,
seq_ord number(6) constraint t1_sqo_nn not null ,
small_vc varchar2(10)) pctfree 90 pctused 10
/
Table created.
SQL> create sequence t1_seq ;
Sequence created.
SQL> create or replace procedure t1_load(i_tag varchar2) as
m_date date ;
begin
for i in 0..25 loop
m_date := trunc(sysdate) + i ;
for j in 1..200 loop
insert into t1 values ( m_date, t1_seq.nextval, i_tag||j) ;
commit ;
dbms_lock.sleep(0.01);
end loop;
end loop;
end ;
/
Procedure created.
-- 다중 세션에서 동시에 Insert 수행
SQL> execute t1_LOAD('a');
PL/SQL procedure successfully completed.
SQL> execute t1_LOAD('b');
PL/SQL procedure successfully completed.
SQL> execute t1_LOAD('c');
PL/SQL procedure successfully completed.
SQL> execute t1_LOAD('d');
PL/SQL procedure successfully completed.
SQL> execute t1_LOAD('e');
PL/SQL procedure successfully completed.
SQL> create index t1_i1 on t1 ( date_ord, seq_ord ) ;
Index created.
SQL> begin
dbms_stats.gather_table_stats ( user ,'t1', cascade => true, estimate_percent=>null, -
method_opt => 'for all columns size 1');
end ;
/
PL/SQL procedure successfully completed.
SQL> select blocks , num_rows from user_tables where table_name ='T1';
BLOCKS NUM_ROWS
---------- ----------
754 26000
SQL> select index_name, blevel, leaf_blocks, clustering_factor from user_indexes
2 where table_name ='T1';
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
------------------------------ ---------- ----------- -----------------
T1_I1 1 87 1342
SQL>
alter session set "_optimizer_cost_model"=io ;
Session altered.
SQL> alter session set "_optimizer_skip_scan_enabled"=false;
Session altered.
SQL> set autotrace traceonly explain
SQL> select count(small_vc) from t1 where date_ord = trunc(sysdate)+7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 515789116
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 57 |
| 1 | SORT AGGREGATE | | 1 | 13 | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 1000 | 13000 | 57 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 1000 | | 5 |
----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DATE_ORD"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
SQL> set autotrace off
비용 계산
Cost =
Blevel +
Ceil(effective index selectivity*leaf_blocks) +
Ceil(effective table selectivity*clustering_factor)
Cost =
1\+
Ceil(0.03846*86) +
Ceil(0.03846*1,008)
= 1 + 4 + 39 = 44
SQL>
select /*+ full(t1) */ rowid, date_ord, seq_ord, small_vc from t1
where rownum <= 10 ;
ROWID DATE_ORD SEQ_ORD SMALL_VC
------------------ --------------- ---------- ----------
AAANFyAABAAAO/SAAA 18-JUN-09 5201 a1
AAANFyAABAAAO/SAAB 18-JUN-09 5202 a2
AAANFyAABAAAO/SAAC 18-JUN-09 5203 a3
AAANFyAABAAAO/SAAD 18-JUN-09 5204 a4
AAANFyAABAAAO/SAAE 18-JUN-09 5205 a5
AAANFyAABAAAO/SAAF 18-JUN-09 5206 a6
AAANFyAABAAAO/SAAG 18-JUN-09 5207 a7
AAANFyAABAAAO/SAAH 18-JUN-09 5208 a8
AAANFyAABAAAO/SAAI 18-JUN-09 5209 a9
AAANFyAABAAAO/SAAJ 18-JUN-09 5210 a10
10 rows selected.
Storage ( freelists 5 )
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 86 24136
1 row selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3693069535
-----------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
-----------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 74 |
| 1 | SORT AGGREGATE | | 1 | 13 | |
|* 2 | TABLE ACCESS FULL| T1 | 1000 | 13000 | 74 |
-----------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("DATE_ORD"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
SQL>
select dump(date_ord,16) date_dump, dump(seq_ord,16) seq_dump
from t1
where date_ord = to_date('18-jun-2009') and seq_ord = 39 ;
DATE_DUMP SEQ_DUMP
---------------------------------- -------------------------------
Typ=12 Len=7: 78,6d,6,12,1,1,1 Typ=2 Len=2: c1,28
1 row selected.
그러나 이 값을 뒤집으면
SQL> select dump(reverse(date_ord),16) date_dump, dump(reverse(seq_ord), 16) seq_dump from t1
2 where date_ord = to_date('18-jun-2009') and seq_ord = 39 ;
DATE_DUMP SEQ_DUMP
---------------------------------------- ----------------------------------------
Typ=12 Len=7: 1,1,1,12,6,6d,78 Typ=2 Len=2: 28,c1
1 row selected.
SQL> create index t1_i1 on t1(date_ord, seq_ord);
Index created.
SQL> begin
2 dbms_stats.gather_table_stats(
3 user,
4 't1',
5 cascade => true,
6 estimate_percent => null,
7 method_opt => 'for all columns size 1'
8 );
9 end;
10 /
PL/SQL procedure successfully completed.
SQL> select blocks, num_rows from user_tables
where table_name = 'T1';
BLOCKS NUM_ROWS
---------- ----------
744 26000
1 row selected.
SQL> select index_name, blevel, leaf_blocks, clustering_factor
from user_indexes
where table_name = 'T1' ;
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 86 801
1 row selected.
SQL> set autotrace traceonly explain
SQL> select count(small_vc)
from t1
where date_ord = trunc(sysdate) + 7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 515789116
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 36 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 1000 | 13000 | 36 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 1000 | | 5 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DATE_ORD"=TRUNC(SYSDATE@!)+7)
SQL> set autotrace off
SQL> alter index t1_i1 rebuild reverse;
Index altered.
SQL> begin
2 dbms_stats.gather_table_stats(
3 user,
4 't1',
5 cascade => true,
6 estimate_percent => null,
7 method_opt => 'for all columns size 1'
8 );
9 end;
10 /
PL/SQL procedure successfully completed.
SQL> select blocks, num_rows
from user_tables
where table_name = 'T1';
BLOCKS NUM_ROWS
---------- ----------
744 26000
1 row selected.
SQL> select index_name, blevel, leaf_blocks, clustering_factor
From user_indexes
Where table_name = 'T1' ;
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 86 25979
1 row selected.
SQL> set autotrace traceonly explain
SQL> select count(small_vc) from t1
where date_ord = trunc(sysdate) + 7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3693069535
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 166 (2)| 00:00:02 |
| 1 | SORT AGGREGATE | | 1 | 13 | | |
|* 2 | TABLE ACCESS FULL| T1 | 1000 | 13000 | 166 (2)| 00:00:02 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("DATE_ORD"=TRUNC(SYSDATE@!)+7)
SQL> set autotrace off
SQL> create tablespace test_8k_assm
blocksize 8k
datafile '/u02v/dbatest/DBATEST/test_8k_assm.dbf'
size 50m extent management local
uniform size 1m segment space management auto
BLOCKS NUM_ROWS
---------- ----------
754 26000
1 row selected.
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 86 23044
1 row selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3693069535
-----------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
-----------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 74 |
| 1 | SORT AGGREGATE | | 1 | 13 | |
|* 2 | TABLE ACCESS FULL| T1 | 1000 | 13000 | 74 |
-----------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("DATE_ORD"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
SQL> select ct,count(*)
from
(
select block, count(*) ct
from
(
select
distinct dbms_rowid.rowid_block_number(rowid) block,
substr(small_vc, 1,1)
from t1
)
group by block
)
group by ct
;
CT COUNT(*)
---------- ----------
5 11
1 461
3 62
2 188
4 5
5 rows selected.
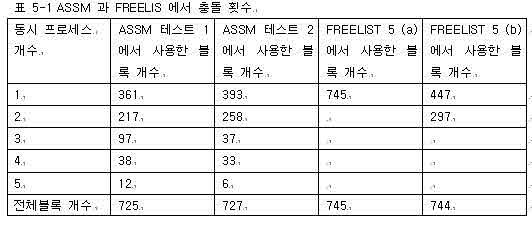
STORAGE ( FREELIST GROUPS 5 )
create table t1
pctfree 90
pctused 10
as
select
trunc((rownum-1)/ 100) clustered,
mod(rownum - 1, 100) scattered,
lpad(rownum,10) small_vc
from
all_objects
where
rownum <= 10000
;
Create index t1_i1_good on t1 ( clustered, scattered ) ;
Create index t1_i2_bad on t1 (scattered, clustered ) ;
BLOCKS NUM_ROWS
---------- ----------
278 10000
select index_name, blevel, leaf_blocks, clustering_factor
from user_indexes
where table_name = 'T1'
;
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I2_BAD 1 24 10000
T1_I1_GOOD 1 24 278
2 rows selected.
set autotrace traceonly explain
select
/*+ index(t1 t1_i1_good) */
count(small_vc)
from
t1
where
scattered = 50
and clustered between 1 and 5
;
Execution Plan
----------------------------------------------------------
Plan hash value: 1877155477
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 16 | 4 |
| 1 | SORT AGGREGATE | | 1 | 16 | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 6 | 96 | 4 |
|* 3 | INDEX RANGE SCAN | T1_I1_GOOD | 6 | | 3 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("CLUSTERED">=1 AND "SCATTERED"=50 AND "CLUSTERED"<=5)
filter("SCATTERED"=50)
Note
-----
- cpu costing is off (consider enabling it)
select
/*+ index(t1 t1_i2_bad) */
count(small_vc)
from
t1
where
scattered =50
and clustered between 1 and 5
;
Execution Plan
----------------------------------------------------------
Plan hash value: 2775871337
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 16 | 9 |
| 1 | SORT AGGREGATE | | 1 | 16 | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 6 | 96 | 9 |
|* 3 | INDEX RANGE SCAN | T1_I2_BAD | 6 | | 2 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("SCATTERED"=50 AND "CLUSTERED">=1 AND "CLUSTERED"<=5)
Note
-----
set autotrace off
create table t1
as
select
sysdate + trunc((rownum-1) / 500) movement_date,
trunc(dbms_random.value(1,60.999)) product_id,
trunc(dbms_random.value(1,10.000)) qty,
lpad(rownum,10) small_vc,
rpad('x',100) padding
from
all_objects
where
rownum <= 10000
;
create index t1_i1 on t1(movement_date);
begin
dbms_stats.gather_table_stats(
user,
't1',
cascade => true,
estimate_percent => null,
method_opt => 'for all columns size 1'
);
end;
/
Select blocks, num_rows
From user_tables
Where table_name = 'T1';
select index_name, blevel, leaf_blocks, clustering_factor
from user_indexes
where table_name = 'T1';
set autotrace traceonly explain
-- 인덱스 컬럼 추가를 권장하는 예제
select sum(qty)
from t1
where movement_date = trunc(sysdate) + 7
and product_id = 44
;
-- 인덱스 변경으로 불리해지는 예제
Select product_id, max(small_vc)
from t1
where movement_date = trunc(sysdate) + 7
group by product_id
;
set autotrace off
BLOCKS NUM_ROWS
---------- ----------
182 10000
1 row selected.
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 27 182
1 row selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 515789116
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 14 | 12 |
| 1 | SORT AGGREGATE | | 1 | 14 | |
|* 2 | TABLE ACCESS BY INDEX ROWID| T1 | 8 | 112 | 12 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 500 | | 2 |
----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("PRODUCT_ID"=44)
3 - access("MOVEMENT_DATE"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
Execution Plan
----------------------------------------------------------
Plan hash value: 3571608589
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 60 | 1320 | 38 |
| 1 | HASH GROUP BY | | 60 | 1320 | 38 |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 500 | 11000 | 12 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 500 | | 2 |
----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("MOVEMENT_DATE"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
drop index t1_i1;
create index t1_i1 on t1(movement_date, product_id);
begin
dbms_stats.gather_table_stats(
user,
't1',
cascade => true,
estimate_percent => null,
method_opt => 'for all columns size 1'
);
end;
/
Select index_name, blevel, leaf_blocks, clustering_factor
from user_indexes
where table_name = 'T1' ;
set autotrace traceonly explain
select sum(qty)
from t1
where movement_date = trunc(sysdate) + 7
and product_id = 44;
select product_id, max(small_vc)
from t1
where movement_date = trunc(sysdate) + 7
group by product_id
;
set autotrace off
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
-------------------- ---------- ----------- -----------------
T1_I1 1 31 6645
1 row selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 515789116
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 14 | 7 |
| 1 | SORT AGGREGATE | | 1 | 14 | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 8 | 112 | 7 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 8 | | 1 |
----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("MOVEMENT_DATE"=TRUNC(SYSDATE@!)+7 AND "PRODUCT_ID"=44)
Note
-----
- cpu costing is off (consider enabling it)
Execution Plan
----------------------------------------------------------
Plan hash value: 2967276995
-----------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
-----------------------------------------------------------
| 0 | SELECT STATEMENT | | 60 | 1320 | 45 |
| 1 | HASH GROUP BY | | 60 | 1320 | 45 |
|* 2 | TABLE ACCESS FULL| T1 | 500 | 11000 | 19 |
-----------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("MOVEMENT_DATE"=TRUNC(SYSDATE@!)+7)
Note
-----
- cpu costing is off (consider enabling it)
데이터 딕셔너리 조작하기
Alter table x enable row movement ;
Alter table x shrink space compact ;
Alter table x shrink space ;
- 강좌 URL : http://www.gurubee.net/lecture/3978
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.