관계형 데이터 모델링 프리미엄 가이드 DB구축 (2014년)
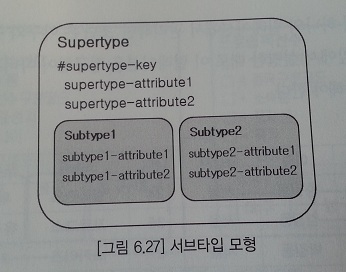
서브 타입의 물리모델 변환
- 서브 타입 구조를 실제 물리 구조로 변환하는 것은 물리 모델링 단계이다.
- 하지만 모델 구조를 확정하는 것은 빠를 수록 좋다.(필자의 생각)
- 서브타입으로 도출된 엔티티는 핵심적인 엔티티일 가능성이 커 물리 모델링 단계에서 변경되면 영향이 크기 때문
서브타입 분할 방법
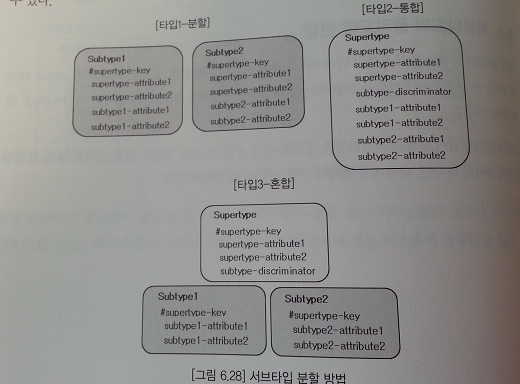
타입1-분할
- 서브타입별 업무가 서로 독립적일 때
- 서브타입별 속성이 많이 다를 때
- 서브타입별 관계가 많이 다를 때
- 모든 서브타입을 동시에 조회하는 경우가 드물 때
- 서브타입별 주 식별자가 상호 배타적이 아닐 때
- 서브타입이 업무적으로 서로 약 결합(Loosely Coupled) 관계일 때
타입2-통합
- 서브타입별 고유 속성이 적을 때
- 속성이 지속적으로 늘어날 가능성이 작을 때
- 하나의 서브타입은 속성도 많고 업무도 중요하며 나머지 서브타입은 덜 중요할 때
- 서브타입 전체를 대상으로 하는 업무가 빈번할 때
- 데이터 건수가 많지 않을 때
- 업무가 중요하지 않을 때
- 서브타입이 서로 포함(Included) 관계일 때
- 서브타입이 업무적으로 서로 강 결합(Tightly Coupled) 관계일 때
타입3-혼합
- 서브타입별 공통 속성을 대상으로 하는 업무가 빈번할 때
- 통합(타입2)하면 속성 개수가 너무 많아질 때
- 업무의 변화가 빈번해 속성이 자주 추가될 때
- 서브타입별 고유 속성이 많을 때
- 트랜잭션의 락(Lock)을 방지하기 위해 엔티티를 분리해야 할 때
- 공통 업무와 고유 업무가 다양하게 존재할 때
- 중요 속성과 참고 속성으로 분리될 수 있을 때
- 슈퍼타입의 조회가 빈번하고 조회 범위가 넓을 때
- 서브타입이 업무적으로 서로 강 결합(Tightly Coupled) 관계일 때
예제
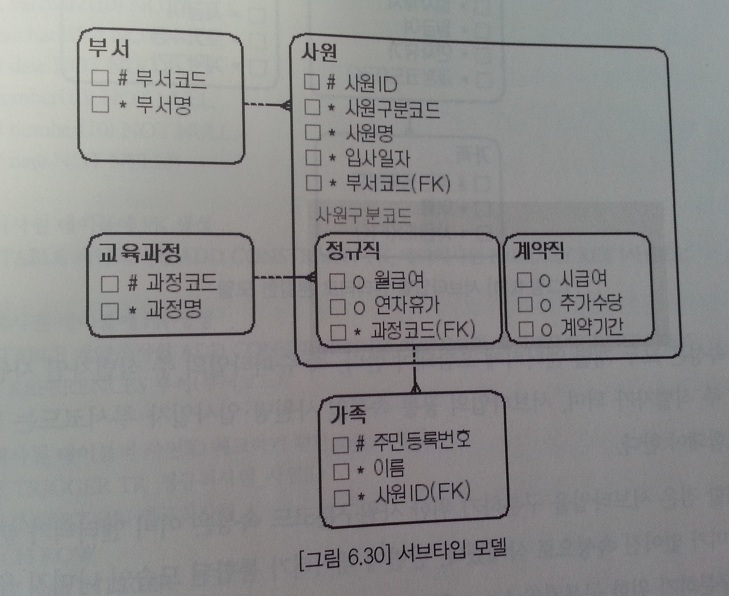
서브타입별 엔티티로 분할(타입1)
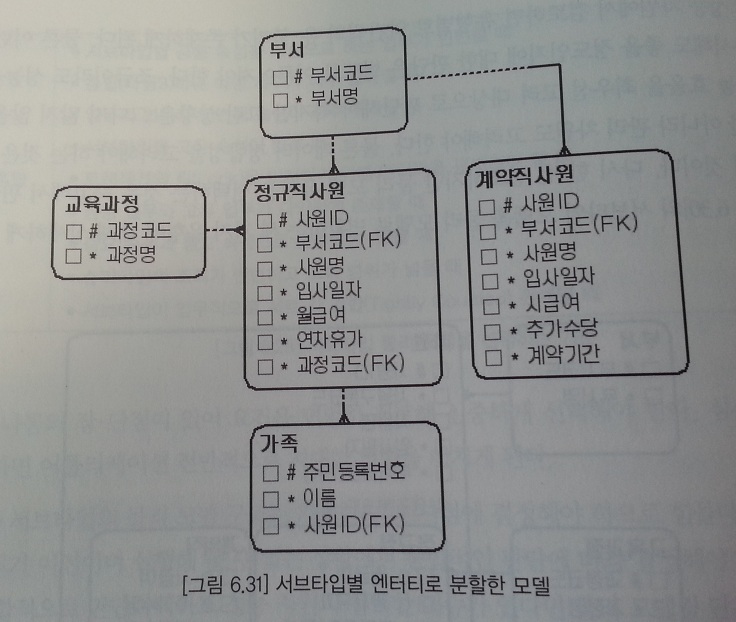
- 별도 엔티티 생성시 엔티티명을 숙고해서 결정한다.(정규직 -> 정규직사원, 계약직 -> 계약직사원)
- 슈퍼타입의 속성은 모두 개별 엔티티에 포함되어야 한다.(사원ID, 사원명, 입사일자, 부서코드)
- 서브타입의 구분자 역할을 하던 사원구분코드 속성은 삭제한다.
- 사원ID가 정규직 사원이나 계약직 사원 사이에서 중복되는 것을 체크하기 위한 트리거
-- 정규직사원 테이블의 사원ID 체크하기 위한 trigger 생성
CREATE TRIGGER TR_정규직사원_사원ID
BEFORE INSERT ON 정규직사원
FOR EACH ROW
DECLARE num INTEGER
BEGIN
SELECT COUNT(*) INTO num FROM 계약직사원 WHERE 사원ID = :NEW.사원ID
IF(num > 0) THEN
--에러 처리
END IF;
END;
-- 계약직사원 테이블의 사원ID 체크하기 위한 trigger 생성
CREATE TRIGGER TR_계약직사원_사원ID
BEFORE INSERT ON 계약직사원
FOR EACH ROW
DECLARE num INTEGER
BEGIN
SELECT COUNT(*) INTO num FROM 정규직사원 WHERE 사원ID = :NEW.사원ID
IF(num > 0) THEN
--에러 처리
END IF;
END;
- 어플리케이션에서 이런 로직을 구현할수도 있지만 데이터베이스에서 원천적으로 체크하는 것이 바람직
- 필자의 의견: 비슷한 유형의 엔티티를 통합된 데이터로 관리하기 위해 일반화한것인데 다시 별도의 엔티티로 돌아가기 때문에 회의적인 입장
상대적 장점
- 엔티티의 속성이 근본적으로 구분되므로 엔티티를 명확하게 관리할 수 있다.
- 개별 서브타입을 사용하는 요건(조회)이 많을때 효율적이다.
- 각 엔티티에 해당하는 업무에 대해 상호 영향을 미치지 않고 처리할 수 있다. 즉 정규직사원 엔티티에 속성을 추가할 때 계약직사원 엔티티에 영향을 끼치지 않는다.
- 각 엔티티의 크기가 줄어든다.
- 정규직사원과 계약직사원 엔티티를 동시에 조회하는 요건이 없다면(Loosely Coupled) UNION 구문이 필요없으므로 성능 면에서 유리하다. 또한 슈퍼타입과 서브타입 엔티티의 조인(Join)이 필요 없으므로 성능에 유리하다.
- 널(Null) 값을 갖는 속성이 줄어든다.
상대적 단점
- 정규직 사원과 계약직 사원을 동시에 조회하는 요건이 있을때(Tightly Coupled) UNION 등이 발생하며 SQL이 복잡해지고 성능 면에서 불리해진다.
- 사원구분코드 속성과 같이 서브타입을 구분하는 속성을 업무에서 사용하면 처리하기 불편하다.
- 시퀀스나 채번 관리 엔티티를 사용해 주 식별자 값을 생성하기 복잡하다.
- 업무는 개별적으로 처리돼도 데이터는 통합된 모습이 아니므로 DW등의 요건에 의해 조회가 복잡해질 수 있다.
- 속성이 반복됨으로써 넓은 의미로 1정규형이 아니다.
하나의 엔티티로 통합(타입2)
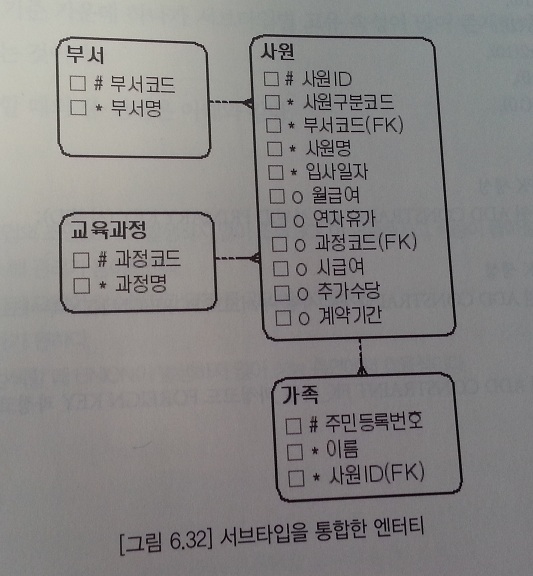

- 슈퍼타입에 통합되므로 슈퍼타입명을 따른다.(사원)
- 서브타입을 구분하는 사원구분코드 속성이 반드시 존재한다.
- 다른 서브타입에 해당하는 속성의 값은 NULL이 되므로 NULL값이 많이 발생한다.
- 업무 규칙을 반영한 CHECK 제약조건(모델만으로는 업무규칙을 알 수 없으므로 추가하여 관리)
CONSTRAINT ck_사원구분
CHECK ((사원구분코드 = '정규직' AND
월급여 IS NOT NULL AND
연차휴가 IS NOT NULL AND
과정코드 IS NOT NULL AND
시급여 IS NULL AND
추가수당 IS NULL AND
계약기간 IS NULL)
OR
(사원구분코드 = '계약직' AND
월급여 IS NULL AND
연차휴가 IS NULL AND
과정코드 IS NULL AND
시급여 IS NOT NULL AND
추가수당 IS NOT NULL AND
계약기간 IS NOT NULL));
- 필자의 의견: 데이터를 가능한 통합하는 것이 원칙으로 핵심적인 엔티티가 아니라면 이처럼 하나의 엔티티로 통합
- 어플리케이션에서 빈번히 사용되는 중요한 엔티티라면 서브타입별 고유 속성이 많이 존재하며 지속적으로 늘어날 가능성이 있는지등의 기준으로 타입을 결정한다.
상대적 장점
- 슈퍼타입과 서브타입의 조인이 발생하지 않아 조회 SQL이 단순해지고 성능이 좋아질 때가 많다.
- 엔티티의 수가 감소해 관리가 용이해진다.
- 복잡한 관계가 없어져 모델이 단순해지고 ERD를 관리하기 편하다.
- 주 식별자를 관리히가 편하다.
- 전체 서브타입을 검색할 때 UNION이 발생하지 않아 성능 측면에서 효율적이다.
상대적 단점
- 엔티티의 속성 개수와 인덱스가 많아져 크기가 증가한다.
- NULL값이 존재하는 속성이 많아진다.
- 정규직 사원이나 계약직 사원에 대한 업무가 추가되거나 변경되면 어플리케이션에 끼치는 영향이 커진다.
- 업무 규칙을 모델에 표현하기 어렵다.
- 공통 속성만을 조회하는 요건이 빈번하거나 조회 범위가 넓으면 IO가 많아져 성능이 나빠진다.
- 엔티티의 정체성이 희석될 수 있다.
- 서브타입 해당 속성에 NOT NULL 제약을 설정할 수 없다.
통합 엔티티와 개발 엔티티 혼합(타입3)
- 슈퍼타입과 서브타입 도출 의도를 가장 잘 반영한 모델로 업무 규칙이 잘 반영돼 커뮤니케이션이 원활해진다.
- 데이터가 주로 함께 사용돼 통합하는 게 좋지만 통합하면 속성 개수가 너무 많아질 때 유용하게 사용된다.
- 통합 엔티티: 공통 속성 + 자주 사용되는 속성, 개별 엔티티: 고유 속성(필자의 의견)
- 사원 엔티티에 존재하는 공통 속성 위주로 수행되는 업무가 많다면 이 방법을 사용한다.
- 서브 타입별로 고유 속성이 많을 때는 서브 타입간의 데이터 성격이 다르다는 것을 의미하므로 위와 같이 구분하는 것이 좋다.
- 해당 엔티티가 업무적으로 자주 사용되는 중요한 엔티티이며 슈퍼타입 엔티티만으로 업무가 빈번하게 처리될 때 선택한다.
- 서브타입을 구분하는 사원구분코드 속성은 반드시 존재해야 한다.
상대적 장점
- 슈퍼타입인 통합 엔티티의 한블록에 많은 인스턴스가 저장되므로 핵심 조회 요건의 성능이 좋아질 때가 많다.
- 모델에 업무 규칙이 표현되므로 모델의 가독성이 높아진다.
- 추가 업무로 말미암은 어플리케이션 변경 영향이 줄어든다. 즉, 변경 요건이 사원/계약직사원/정규직사원 엔티티에 분산되며 슈퍼타입인 사원 엔티티에 속성이 추가되지 않도록 관리할 수 있다.
- 집계나 DW의 요건을 만족할 가능성이 커진다. 이는 반드시 필요한 것은 아니지만 전사 차원에서 고려하면 바람직하다.
- 데이터 저장 공간을 가장 효율적으로 사용한다.
상대적 단점
- 조회 요건에 따라 조인이나 조인후의 유니온등이 발생해 성능 효율이 떨어질 있다.
- 여러 엔티티로 나뉘어 관리가 어려워진다.
- 배타/중복/Complete/Incomplete 서브타입의 종류에 따라 인스턴스를 발생시키는데 있어 혼선이 발생할 수 있다.
- 계약직사원/정규직사원 에티티의 주 식별자 값이 띄엄띄엄 생긴다.
슈퍼타입 엔티티가 상위 엔티티인 모델
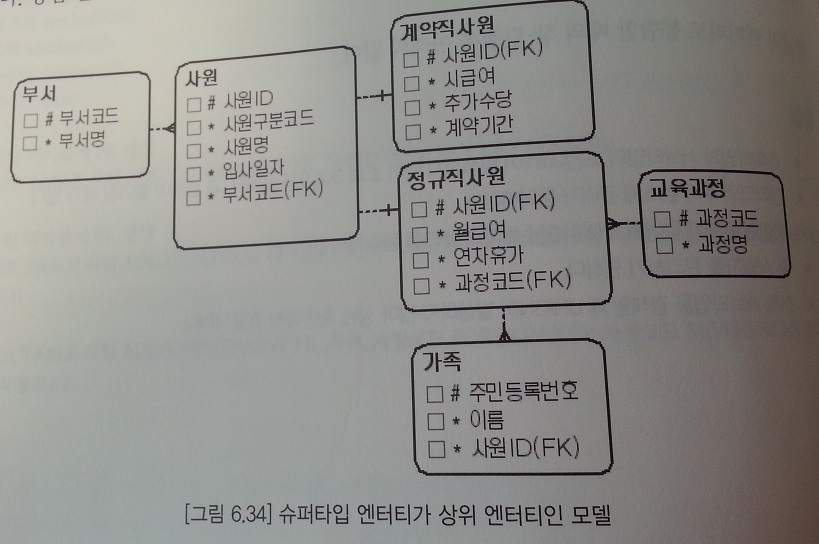
- 통합 엔티티와 개별 엔티티 사이에 1:1 관계가 발생한다.
- 중복 서브타입이나 Incomplete 서브타입 등 모든 서브타입을 관리할 수 있는 모델이다.
서브타입 엔티티가 상위 엔티티인 모델
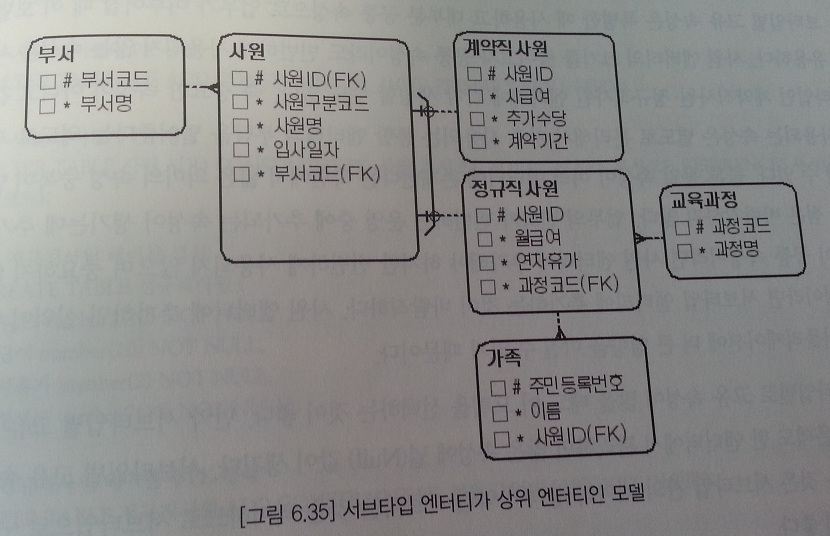
- 배타 서브타입과 Complete 서브타입 모델(가장 많이 발생)
- 서브타입을 배타 관계로 관리하면 보통 RI(Reference Integrety)를 생성할 수 없다.
- 서브타입을 배타 관계로 관리하면 주 식별자를 관리하기 복잡해진다.
예제
- 서브타입인 개인고객과 법인고객이 슈퍼타입인 고객 엔티티와 배타 관계가 존재하는 모델
- 배타 관계를 가지는 서브타입 모델
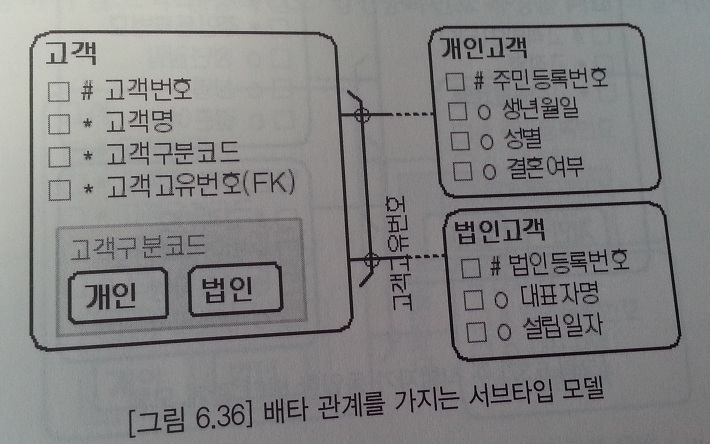
- 고객 엔티티의 주 식별자는 인조 식별자인 고객번호이다.
- 개인고객과 법인고객은 상호 배타적이므로 고객고유번호라는 하나의 통합된 속성으로 관리한다.(주민등록번호 OR 법인등록번호)
- 고객고유번호 속성은 NOT NULL 속성을 가지며 고객구분코드와 고객고유번호를 묶어 유니크 인덱스로 생성하면 원천적으로 업무규칙을 관리해 무결성 유지가 가능하다.
- 고객구분코드라는 구분자를 관리한다.
- 고객 엔티티보다 개인고객/법인고객 엔티티에 데이터가 먼저 발생한다.
- 주민등록번호는 변경될 수 있어 주 식별자로 사용하기 무리가 있다.
주 식별자가 동일한 배타 관계 모델
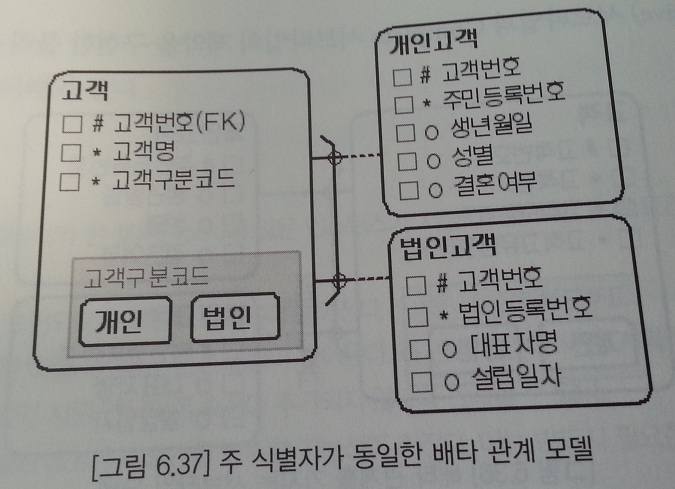
- 개인고객 엔티티에 데이터를 insert 할때 고객번호를 체크하기 위해 트리거가 필요하다.(법인고객도 필요)
CREATE TRIGGER tg_개인고객_고객번호
BEFORE INSERT OR UPDATE OF 고객번호
ON 개인고객
FOR EACH ROW
DECLARE
num INTEGER := 0;
BEGIN
IF (INSERTING OR
(UPDATING AND :new.고객번화 <> :old.고객번호)) THEN
SELECT COUNT(*)
INTO num
FROM 법인고객
WHERE 고객번호 = :new.고객번호
IF(num <> 0) THEN
--에러 처리
END IF;
END IF;
END;
- 아니면 고객 엔티티에서 고객번호를 관리하거나 어플리케이션에서 로직으로 체크한다.
- 고객의 고객번호에 대해 개인고객/법인고객의 고객번호와 모두 참조 무결성 제약을 설정할 수 없다.
배타 속성을 사용하지 않는 배타 관계 모델
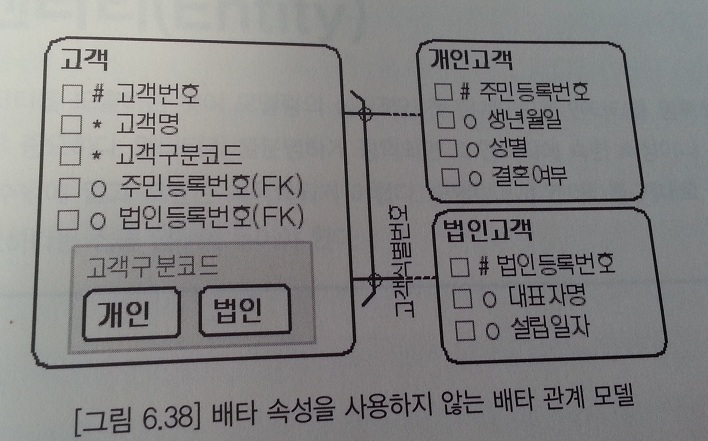
- '고객고유번호' 대신 주민등록번호/법인등록번호 속성을 FK로 사용한다.
- 고객 엔티티의 주민등록번호/법인등록번호 속성은 NULLABLE 해야 한다.
- 둘 중의 하나만 반드시 존재해야 한다는 관계를 제약하기 위해 아래와 같은 함수기반인덱스를 생성할 수도 있다.
CREATE UNIQUE INDEX IX_고객 ON 고객(CASE WHEN 고객구분코드 = '개인' THEN 주민등록번호 WHEN 고객구분코드 = '법인' THEN 법인등록번호 END)
- 배타 관계의 두속성을 별도로 관리하면 조회 요건을 복잡하게 만들기 때문에 이런 모델은 자주 사용되지 않는다.
"구루비 데이터베이스 스터디모임" 에서 2014년에 "관계형 데이터 모델링 프리미엄 가이드" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/3608
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.