이펙티브 오라클 (2009년)
1. 파티셔닝의 개요
1.1. 파티셔닝이란?
- Oracle V8.0에서 도입
- 큰 테이블이나 인덱스를 관리하기 쉬운 조각으로, 물리적으로 분할하는 것을 의미함
- 물리적인 데이터 분할이 있더라도, DB에 접근하는 Application의 입장에서는 이를 인식하지 못함
- Data Partitioning은 큰 테이블과 인덱스의 관리를 보다 쉽게 하기 위해 설계됨
1.2. 파티셔닝 사용의 이점
가용성(Availability)
- 물리적인 Partitioning으로 인해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성이 향상된다.
관리용이성(Manageability)
- Data-Base의 큰 객체들을 제거하여 관리를 쉽게 해줌
성능(Performance)
- 특정 DML과 Query의 성능을 향상시킴, 주로 대용량 DW 환경에서 효율적
- 많은 Insert가 있는 OLTP 시스템에서 Insert 작업들을 분리된 파티션들로 분산시켜 경합을 줄임 (Hot spot 을 분산)
2. 파티셔닝 테이블
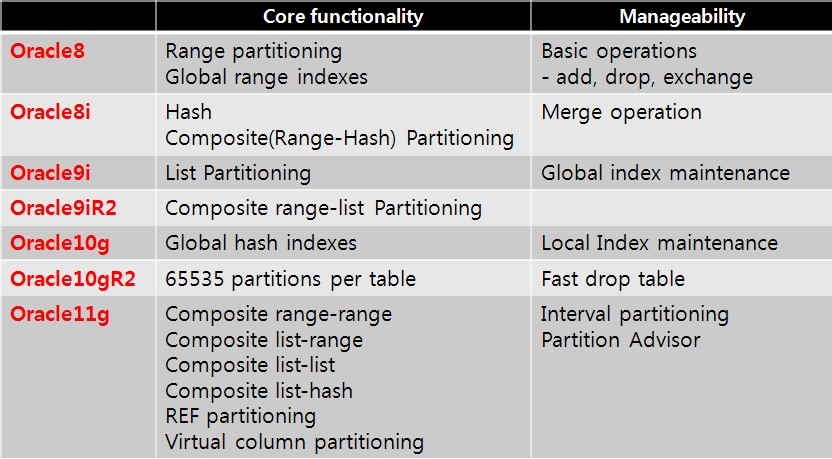
2.1. 오라클 버전별 지원되는 파티셔닝 기법
2.2. Range Partition
- 날짜 기준 Partition
- 일별, 월별, 분기별 등 의 데이터에 적합
- Historical Data Table에적합 한 Partitioning
- 손쉬운 관리 기법 제공 에 따른 관리 시간의 단축
일반적인 Range Parition
CREATE TABLE part_range (
ymd VARCHAR2(14),
empno NUMBER
)
TABLESPACE tbs_part01
PARTITION BY RANGE (ymd) (
PARTITION p200908 VALUES LESS THAN ('20090901000000')
TABLESPACE tbs_part05,
PARTITION VALUES LESS THAN (MAXVALUE)
);
- ymd 에 의해서 범위 분할 이 이루어진다.
- P200908 파티션과 SYS_Pnnnn 이렇게 두 개의 파티션이 생성된다.
- Partition p200908에는 20090901000000 보다 작은 값들이 모두 저장된다.
- 20090901000000보다 큰 값들은 SYS_Pnnnn 에 저장된다.
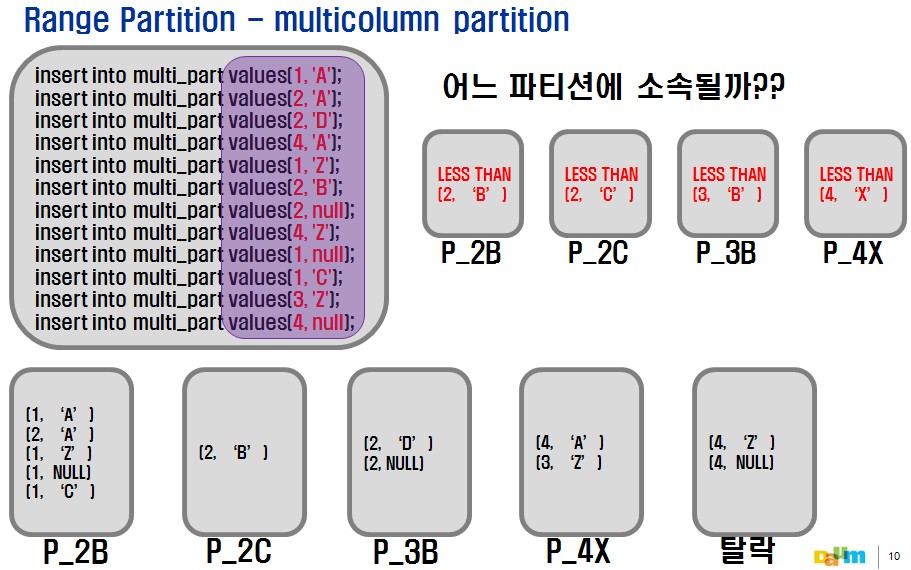
multicolumn Range Partition
- Range Partition을 이용하여 좀더 세분화된 분류 를 원할때 사용된다.
- Partition-Key에 열거된 순서가 중요하며, 2번째 키 값 은 첫 번째 키 값이 동일할 경우 비교 된다.
CREATE TABLE multi_part (
unit NUMBER(1), subunit CHAR(1)
)
PARTITION BY RANGE ( unit, subunit ) (
PARTITION P_2b VALUES LESS THAN (2,'B'),
PARTITION P_2c VALUES LESS THAN (2,'C'),
PARTITION P_3b VALUES LESS THAN (3,'B'),
PARTITION P_4x VALUES LESS THAN (4,'X')
);
2.3. Hash Partition
- Partition Key의 Hash값에 의한 Partitioning (균등한 데이터 분할 가능)
- 좋은 분포도를 얻기 위해선 2의 제곱수로 Partitioning 하는것이 좋다.
- Select시 조건과 무관하게 병렬 Degree 제공 (질의 성능 향상)
- 특정 Data가 어느 Hash Partition에 있는지 판단 불가
- Hash Partition은 파티션을 위한 범위가 없는 데이터에 적합
Hash Partition - Named Partitions
CREATE TABLE part_hash (
empno NUMBER(4),
empname VARCHAR2(20)
)
PARTITION BY HASH (empname) (
PARTITION p_h1 tablespace tbs_part01,
PARTITION p_h2 tablespace tbs_part02
);
- Partition할 column과 파티션의 이름을 직접 기술 할 수 있다.
- 파티션의 수는 2의 제곱수 만큼 지정을 해준다.
- 파티션의 이름을 지정하지 않는다면 SYS_Pnnnn 형태로 자동 지정된다.
Hash Partition - Quantity of Partitions
CREATE TABLE part_hash2 (
empno NUMBER(4),
empname VARCHAR2(20)
)
PARTITION BY HASH (empname)
PARTITIONS 4
STORE IN (tbs_part03, tbs_part04);
- 생성하고자 하는 파티션의 수를 기술 해 준다.
- 파티션의 수는 2의 제곱수 만큼 지정 을 해준다.
- 파티션의 이름은 SYS_Pnnnn 형태로 자동 지정 된다.
- 4개의 파티션은 STORE 절에 기술된 TABLESPACE에 균등하게 생성 된다.
2.4. List Partition
- 특정 Partition에 저장 될 Data에 대한 명시적 제어 가능
- 분포도가 비슷 하며, 많은 SQL에서 해당 Column의 조건이 많이 들어오는 경우 유용 함
- Multi-Column Partition Key 제공 불가
- Partition key 값 은 NULL 값을 포함한 어떠한 값이라도 한번만 명시 가능
- 대소문자를 구분 함, 허용문자 외 문자 입력 에러 발생
CREATE TABLE part_list (
name VARCHAR2(20),
location VARCHAR2(20)
)
PARTITION BY LIST(location) (
PARTITION p_seoul VALUES ('SEOUL')
TABLESPACE tbs_part06,
PARTITION p_jeju VALUES ('JEJU', NULL)
TABLESPACE tbs_part07
);
- Partition key 의 값은 VALUES 절에 기술
- 'VALUES'절에 들어갈 수 있는 값의 크기는 4k 까지 가능
- Part_list 테이블 에는 'SEOUL', 'JEJU', NULL만 저장 가능
2.5. Composite Partition
- Composite Partition 은 Partition의 Sub-Partitioning 을 말한다.
- 큰 파티션에 대한 I/O 요청을 여러 partition으로 분산
- Range Partitioning 할 수 있는 Column이 있지만, partitioning 결과 생성된 partition이 너무 커서 효과적으로 관리할 수 없을 때 유용함
Composite Partition - Range Hash Partitioning
CREATE TABLE part_rh (
empno NUMBER,
empname VARCHAR2(20)
)
PARTITION BY RANGE (empno)
SUBPARTITION BY HASH (empname)
SUBPARTITIONS 4 STORE IN (tbs_part07, tbs_part08) (
PARTITION comp_low VALUES LESS THAN (2000),
PARTITION comp_hi VALUES LESS THAN (4000),
PARTITION comp_max VALUES LESS THAN (MAXVALUE)
);
- 생성하고자 하는 Sub-Partition의 수를 기술
- 파티션의 수는 2의 제곱수 만큼 지정
- Sub-partiton의 이름은 SYS_Pnnnn 형태로 자동 지정
Extended Composite Partition
- Oracle 11g에서 처음 소개됨
- 기존의 Range-Hash, Range-List 만으로 해결 불가능한 Partitioning에 대한 해법 제시
1. Range-Range : 두 개의 날짜 필드를 가지고 있을 때 유용할 수 있다.
2. List-Range : List Partitioning + 날짜필드를 이용한 sub-partitioning
3. List-Hash : List Partitioning 후 생성된 파티션의 크기가 너무 클 경우 Hash Partitioning을 이용하여 sub-partitioning을 하면 유용하다.
4. List-List : List Partitioning을 이용하여 파티션할 수 있는 Column이 2개 이상 있을 경우 유용하다.
2.6. Reference Partitioning
- Oracle 11g에서 처음 소개됨
- 부모 테이블의 Reference Key를 이용하여 자식테이블에 대해서 Partitioning을 수행한다
11g 이전의 문제
- 부모테이블
CREATE TABLE customers (
cust_id NUMBER PRIMARY KEY,
cust_name VARCHAR2(200),
rating VARCHAR2(1) NOT NULL
)
PARTITION BY LIST (rating) (
PARTITION pA VALUES ('A'),
PARTITION pB VALUES ('B')
);
- 자식테이블
CREATE TABLE ref_sales (
sales_id NUMBER PRIMARY KEY,
cust_id NUMBER,
sales_amt NUMBER,
CONSTRAINT fk_sales_01
FOREIGN KEY (cust_id)
REFERENCES customers
);
- Partitioning issue..
- 두 테이블을 같은 방식으로 Partitioning 하는 것이 제일 좋다.
- 부모 테이블의 Partition key는 raiting, 자식테이블은??
- Reference partitioning을 사용하여 해결!!
CREATE TABLE ref_sales (
sales_id NUMBER PRIMARY KEY,
cust_id NUMBER NOT NULL,
sales_amt NUMBER,
CONSTRAINT FK_SALES_01
FOREIGN KEY (cust_id)
REFERENCES customers
)
PARTITION BY REFERENCE (fk_sales_01);
- Partition 정의 시 foreign-key의 이름을 파티션 절에 기술
- Reference Partitioning을 위해선 cust_id 컬럼에 NOT NULL 제약조건이 필수
- 자식 테이블을 위해 긴 Partitioning절을 명시적으로 입력할 필요가 없다.
2.6. Inerval Partitioning
- Oracle 11g에서 처음 소개됨
- Range Partitioning의 단점을 보완한 Partitioning기법으로, Partitioning Interval만 지정해 주면 Oracle이 자동으로 Partition을 생성해 준다.
- 11g 이전의 range partition의 한계점
CREATE TABLE part_range (
ymd DATE,
empno NUMBER
)
PARTITION BY RANGE(ymd) (
PARTITION p200906 VALUES LESS THAN (to_date('2009-07-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss')),
PARTITION p200907 VALUES LESS THAN (to_date('2009-08-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss')),
PARTITION p200908 VALUES LESS THAN (to_date('2009-09-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss'))
);
- 위의 테이블에 2009년 09월 데이터 가 들어간다면 에러 발생
- ORA-14400: inserted partition key does not map to any partition
- 위의 문제를 해결하기 위해서 관리자가 200909 partition을 생성 해 주어야 한다.
Interval Partition으로 문제 해결
CREATE TABLE part_interval (
ymd DATE,
empno NUMBER
)
PARTITION BY RANGE(ymd)
INTERVAL (NUMTOYMINTERVAL(1,'MONTH'))
STORE IN ('TBS_PART05', 'TBS_PART06') (
PARTITION p200908
VALUES LESS THAN (to_date('2009-09-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss'))
);
- Partition 되는 간격을 설정
- 추가적인 Partition 생성을 안 해줘도 된다.
- 새로 생성되는 Partition의 이름은 SYS_Pnnnn 형태로 생성
SQL> select partition_name, high_value from user_tab_partitions where table_name ='PART_INTERVAL';
PARTITION_NAME HIGH_VALUE
------------------------------ -------------------------------------------------------------
P200908 TO_DATE(' 2009-09-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SQL> insert into part_interval values(to_date('2009-09-01 23:00:00', 'yyyy-mm-dd hh24:mi:ss'), 23);
1 row created.
SQL> select partition_name, high_value from user_tab_partitions where table_name ='PART_INTERVAL';
PARTITION_NAME HIGH_VALUE
------------------------------ -------------------------------------------------------------
P200908 TO_DATE(' 2009-09-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P11617 TO_DATE(' 2009-10-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SQL> select * from part_interval partition for (to_date('2009-09-05', 'yyyy-mm-dd'));
YMD EMPNO
------------------- ----------
2009-09-01 23:00:00 22
- Partition의 이름을 모를경우 FOR 절을 이용 , 해당 Partition을 참조 할 수 있다.
- Partition을 TRUNCATE, DROP할 경우에도 사용 가능하다.
2.7. System Partitioning
- Oracle 11g에서 처음 소개됨
- 어떤 논리적인 방법으로도 Partitioning할 수 없는 테이블, Partitioning의 경계값이 모호한 경우 사용한다.
- 파티션 별 데이터 분배는 사용자의 몫 이다.
- 파티션 키나 경계값은 없다 .
CREATE TABLE part_sys (
empname VARCHAR2(20),
account_no NUMBER
)
PARTITION BY SYSTEM (
PARTITION P_EMPNAME
TABLESPACE tbs_part07,
PARTITION P_ACCOUNTNO
TABLESPACE tbs_part08
);
SQL> insert into part_sys values('nalls76', 334299332);
insert into part_sys values('nalls76', 334299332)
*
ERROR at line 1:
ORA-14701: partition-extended name or bind variable must be used for DMLs on tables
partitioned by the System method
SQL> insert into part_sys partition(p_empname) values('nalls76', null);
1 row created.
SQL> insert into part_sys partition(p_accountno) values('jsoem', 3429342938);
1 row created.
- System Partition 은 다른 Partitioning과는 다르게 데이터의 경계값을 알 수 없다.
- Data를 다루는 사람이 적절하게 데이터의 배분 을 해주어야 한다.
2.8. 파티셔닝 테이블의 유용한 기능
1. Query Performance
- 불필요한 Partition에 대한 Access가 지양 ( Partition Pruning )
- Partition wise join (서로 상응하는 Partition간 Parallel Join)
2. 대용량 데이터의 Sort 및 Grouping 작업의 용이
- 필요한 Partition만 Main Memory에 load 함으로서 효율적인 Memory사용이 가능
- Sort 작업 시 물리적 Temporary Segment 사용의 최소화 로 인한 수행속도 향상
3. Data 정리 (과거 Partition Drop or Exchange partition)
- Partition Drop
SQL> ALTER TABLE PART_RANGE DROP PARTITION P200906;
- Partition Exchange
SQL> ALTER TABLE PART_RANGE EXCHANGE PARTITION P200908 WITH TABLE EMP_EXCHANGE WITH VALIDATION;
4. 기존 Partition의 분할
- PART_EMP 테이블에 P200905 파티션을 추가하여 P200906에 들어있는 5월 데이터를 P200905로 분할 해 낸다.
- Partition Split은 Split 기준 값 보다 작은 값은 Into절의 좌측 파티션에, 큰 값은 오른쪽 파티션에 저장 된다.
SQL> ALTER TABLE PART_RANGE SPLIT PARTITION P200906
2 AT(TO_DATE('2009-06-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS'))
3 INTO (PARTITION P200905, PARTITION P200906);
Table altered.
5. Partition 관리 Operations
ALTER TABLE *ADD PARTITION*
ALTER TABLE *DROP PARTITION*
ALTER TABLE *EXCHANGE PARTITION*
ALTER TABLE *MODIFY PARTITION*
ALTER TABLE *MOVE PARTITION* \[PARALLEL\]
ALTER TABLE *RENAME PARTITION*
ALTER TABLE *SPLIT PARTITION* \[PARALLEL\]
ALTER TABLE *MERGE PARTITION* \[PARALLEL\]
ALTER TABLE *COALESCE PARTITION* \[PARALLEL\]
ALTER TABLE *ANALYZE PARTITION*
ALTER TABLE *TRUNCATE PARTITION*
EXPORT / IMPORT \[*PARTITION*\]
SQL*Loader \[DIRECT / PARALLEL\] \[*PARTITION*\]
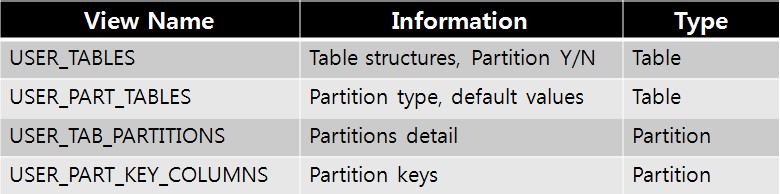
2.9. Partition Table 관련 Dictionary View
3. 파티셔닝 인덱스
- Index 는 Table과 마찬가지로 Partitioning이 가능
- Partitioned Index 또는 Non-Partitioned Index는 Partitioned Table 또는 Non-Partitioned Table과 함께 사용 가능
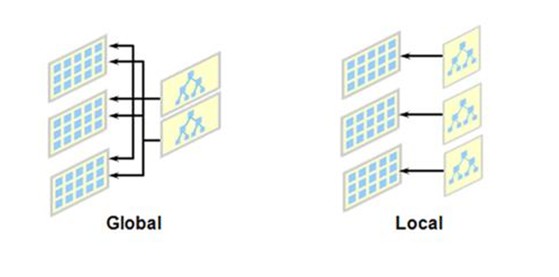
3.1. Global or Local Partitioned Index
- Global Partitioned Index는 Table의 Partition 구조와 별개로 구성
- Global Partitioned Index는 Non-Partitioned Table에 생성 가능
- Local Partitioned Index는 Partitioned Table에만 생성 가능
- Local Partitioned Index는 Table의 Partitioning 구조와 동일하게 Partitioning ( Partitioning Key에 의해 분할 됨)
3.2. Prefixed or Non-prefixed index
- Prefixed index는 Partitioning Key와 Leading Index Key가 동일
- Non-Prefixed Index는 Partitioning Key와 Leading Index Key가 동일하지 않다.
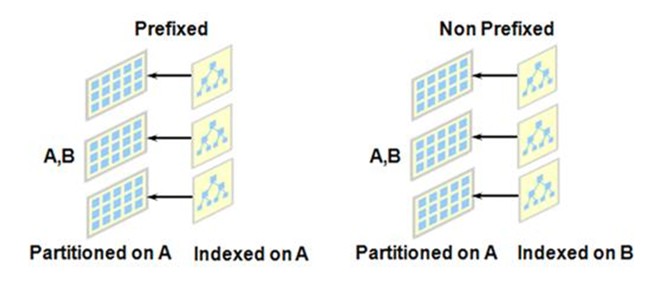
3.3. Index Partitioning의 종류
- Partition Index는 Partition Key와 Partition 개수가 Partition Table과 동일한 경우와 그렇지 않은 경우에 따라 Local or Global Index로 구분 된다.
Partitioned Index의 종류
- Global Index or Local Index
- Prefixed index or Non-prefixed Index
허용되는 Partitioning 종류
- Global Prefixed Index (Not equi-partitioned)
- Local Prefixed Index (equi-partitioned)
- Local Non-Prefixed Index (equi-partitioned)
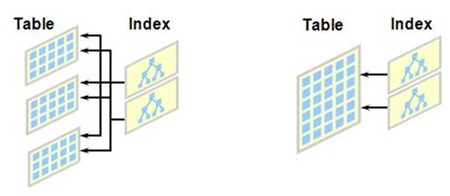
Global Index
- Range Partition, Hash Partition, Prefixed 에서만 사용될 수 있다.
- 하나의 인덱스 파티션이 여러(또는 모든) 테이블 파티션을 가리킬 수 있다.
- 인덱스 파티션 수는 테이블 파티션 수와 다를 수 있다.
- 테이블의 특정 Partition Drop시 Unusable 상태 가 된다.
CREATE TABLE part_global (
ymd DATE,
empno NUMBER
)
PARTITION BY RANGE(ymd) (
PARTITION p200906 VALUES LESS THAN (to_date('2009-07-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss')),
PARTITION p200907 VALUES LESS THAN (to_date('2009-08-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss')),
PARTITION p200908 VALUES LESS THAN (to_date('2009-09-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss'))
);
CREATE INDEX part_global_idx1 ON part_global (empno)
GLOBAL PARTITION BY RANGE (empno) (
PARTITION p_part_global_idx1 VALUES LESS THAN (2000)
TABLESPACE tbs_part03,
PARTITION p_part_global_idx2 VALUES LESS THAN (MAXVALUE)
TABLESPACE tbs_part04
);
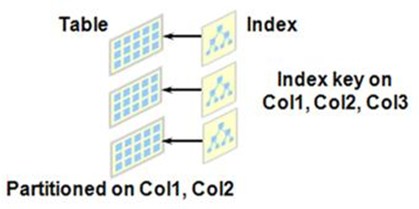
Local Prefixed Index
- Partitioned Table 에만 생성 가능
- Index Key의 leading column과 Index의 Partition Key가 Partition Table과 동일 하다.
CREATE TABLE PART_LOCAL (
rnum NUMBER, sword VARCHAR2(100)
) PARTITION BY RANGE (RNUM) (
PARTITION P_RNUM1 VALUES LESS THAN(100) TABLESPACE tbs_part05,
PARTITION P_RNUM2 VALUES LESS THAN(MAXVALUE) TABLESPACE tbs_part06
);
SQL> CREATE INDEX PART_LOCAL_IDX1 ON PART_LOCAL (RNUM) LOCAL;
Index created.
CREATE INDEX PART_LOCAL_IDX1 ON PART_LOCAL (RNUM)
TABLESPACE tbs_part07
LOCAL (
PARTITION P_LOCAL_IDX1,
PARTITION P_LOCAL_IDX2 TABLESPACE tbs_part08
);
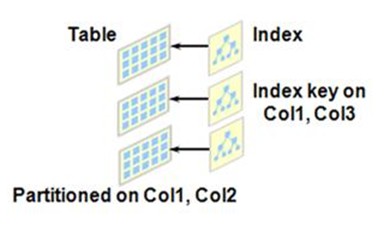
Local Non-Prefixed Index
- Partitioned Table 에만 생성할 수 있다.
- Table Partitioning Key와 Index Partitioning Key는 동일 하다.
- Table partitioning Key와 Index Key는 틀리다.
CREATE TABLE PART_LOCAL_NP (
rnum NUMBER, sword VARCHAR2(100)
) PARTITION BY RANGE (RNUM) (
PARTITION P_RNUM1 VALUES LESS THAN(100) TABLESPACE tbs_part01,
PARTITION P_RNUM2 VALUES LESS THAN(MAXVALUE) TABLESPACE tbs_part02
);
SQL> CREATE INDEX PART_LOCAL_NP_IDX1 ON PART_LOCAL_NP (SWORD) LOCAL;
Index created.
CREATE INDEX PART_LOCAL_NP_IDX2 ON PART_LOCAL_NP (SWORD)
TABLESPACE tbs_part02
LOCAL (
PARTITION P_LOCAL_NP_IDX1,
PARTITION P_LOCAL_NP_IDX2
);
3.4. Index Type and Partitioning
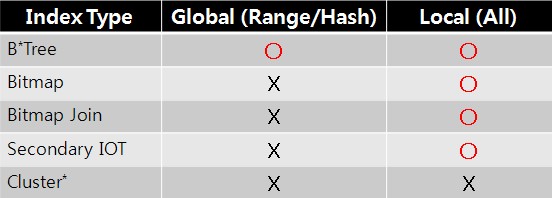
3.5. Index Partiton Status
- Partitioned Table에 DML 발생 : Index에 자동 반영
- Partitioned Table에 DDL 발생 : Index Unusable 상태
- Local Index : 일반적으로 관련된 Partition만 Unusable 상태로 변경
- Global Index : Index 전체가 Unusable 상태로 변경
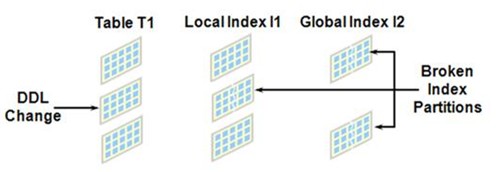
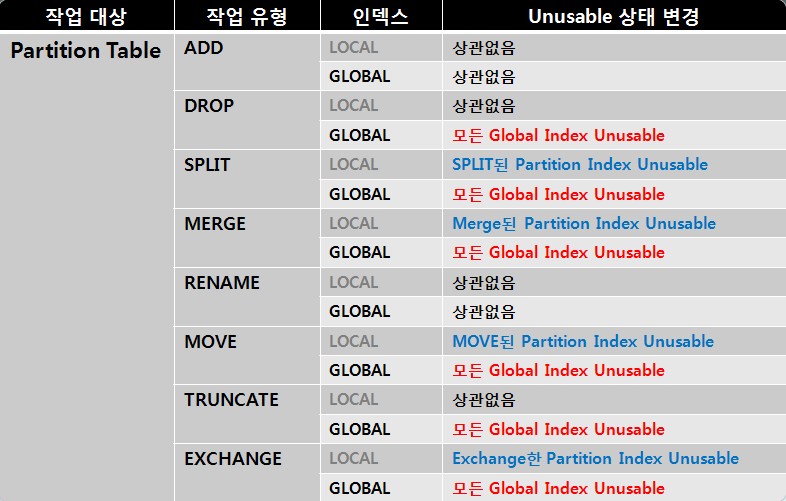
Partitioned Index Rebuild
- Partition Table에 DDL작업을 수행한 후에는 Table에 있는 Index(Local/Global)에 Rebuild 작업을 수행해 주어야 한다.
- 특정 Partition의 Index를 rebuild
SQL> ALTER INDEX PART_LOCAL_IDX1 REBUILD PARTITION P_LOCAL_IDX1;
Non-Partitioned Global Index의 rebuild
SQL> ALTER INDEX PART_GLOBAL_IDX1 REBUILD;
- Partitioned Global Index의 경우 각각의 Partition에 대해서 Rebuild 해주어야 한다. Non-Partitioned Global Index와 같이 Rebuild할 경우 다음과 같은 에러가 발생한다.
- ORA-14086 : 분할 영역된 인덱스는 전체를 다시 만들 수 없습니다.
3.6. Index 관련 Data Dictionary Views
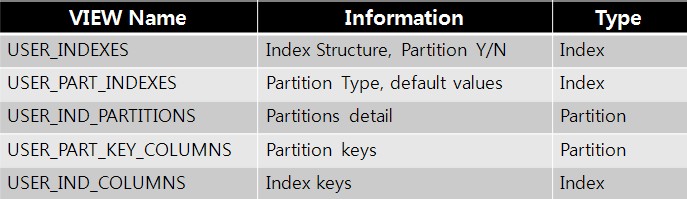
4. 상황에 따른 파티셔닝 기법의 선택
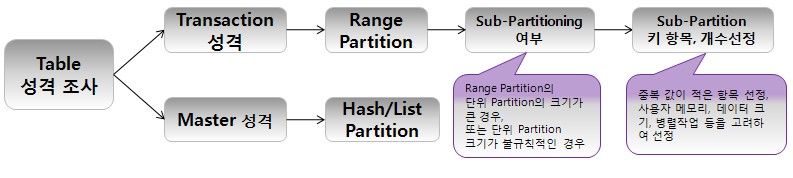
4.1. Partition 방식의 선정
- 기본적인 업무 테이블 의 유형은 Master 성 테이블, Transaction 성격의 Table 그리고 Lookup 성격의 Table이 존재
- Master 성 Table은 대부분 기간개념이 없지만 , Transaction Table 은 기간 개념이 포함 된 경우가 대부분이다.
- Master Table과 Transaction Table은 항상 연관관계가 있으며 Join Operation을 수반한다.
- Partitioning 방식, Partitioning Key, Partition 개수 등을 일관성 있게 부여 함으로서 Query의 효율성을 높일 수 있다.
1. Master Table
- Hash or List Partitioning 을 한다. Hash의 경우 특별한 구분 항목이 없는경우 사용하며, 균등한 데이터 분할을 위한 Partition Key 선정과 System이 고려된 Partition의 크기와 개수 선정이 중요하다.
- List Partition의 경우 특정 항목에 의해 업무가 명확히 구분되어지는 성격의 테이블로서, 지역/부서 항목을 포함한 경우가 대표적이다.
2. Transaction or Summary Table
- 기간 개념의 Table로서 Range or Range + Hash, Range + List 방식을 사용한다.
고려사항
- Master and Transaction Table은 항상 연관관계가 있으므로 일관성 있는 Partition방식이 사용되는 것이 좋다.
- Master Table이 Hash 라면 Transaction Table은 Range+Hash, List 라면 Range+List 방식으로 구성하는 것이 좋다.
4.2. 업무 영역에 따른 Partition 구성
1. Staging / ODS (Operational Data Store) 영역
- 원시데이터가 집적되는 곳 이므로 데이터 로딩을 고려해야 한다.
- 테이블간의 조인 보다는 관리차원의 파티션 방안을 고려한다.
- 기간별 관리측면의 Range 방식을 주로 사용 한다.
- 만약 초기 데이터가 대용량 이라면 Hash 방식 을 사용하여 분할한다.
- 동시작업 보다는 단계별 Bulk작업이 예상되므로, 단위 작업 시 작업 Session에 대한 충분한 메모리(sort area, hash join area)를 할당하여 작업한다.
2. 주제테이블 또는 Summary 테이블 영역 (DW / DM 영역)
- 데이터의 가공, 변환, 생성에 따른 대용량 배치 작업이 예상, 이에 따른 데이터 정렬 및 Grouping 작업에서 사용자 메모리 부족으로 인한 Physical I/O 발생을 최소화 하기 위한 방안이 필요 하다.
- 다양한 Query 및 대량의 정렬작업을 메모리에서 수용할 수 있는 파티션 방안이 필요하며, 병렬성을 고려한 파티션 크기 및 개수의 선정을 고려한다.
- Master성 테이블은 Hash Partition 이 예상되며, 관련된 Transaction Table은 Range+Hash 방식으로 구성, Master Table의 Hash Partition의 개수와 상응하는 방식으로 Transaction Table을 구성하는것이 좋다.
4.3. Partition 개수의 선정
- Range Partition의 경우 기간 정보에 의해 Partition이 결정 되지만, Hash Partition의 경우 설계자가 sub-partition의 개수를 정해야 한다. sub-partition의 개수는 관리 및 수행속도, 특히 대량의 작업과 밀접한 관계가 있다.
예
- 60Gbyte Non-Partitioned Table이 있다고 가정, 이 테이블의 Sorting 작업을 위해선 테이블 크기에 상응하는 메모리가 필요
- 이 경우, 메모리 에서는 일정량의 데이터만 처리가 가능하고 나머지 데이터는 Temporary segment를 이용하게 되므로 빈번한 Disk I/O가 발생
- 60Gbyte의 데이터가 1년치 데이터라 가정한다면, 월별 Partitioning을 했을 경우 5Gbyte의 Partition이 12개 존재 할 것이다.
- Non Partitioned Table의 데이터 정렬을 위해선 총 60G의 데이터를 한번에 해결해야함 Partitioned Table은 데이터 정렬을 위해선 5G의 월단위 데이터의 12번 수행이 필요하다.
- Partition의 수를 늘리면 단위 작업수는 증가하지만, 한번에 처리하는 데이터 양은 상대적으로 줄어든다.
- 이 의미는, 대용량 테이블도 Disk Sort 없이 또는 최소화 하여 수행할 수 있다는 의미
- 물리적인 Disk I/O 없이 메모리만을 사용하여 작업을 한다면 작업횟수와는 상관 없이 수행속도 측면에서나 Disk Storage 활용 측면에서 상당한 이점 이 있다.
- 업무적 특성에 따른 Partition 기준(Partition Key, Partitioning 방법)을 고려 하여
- 대량의 작업을 메모리에서 소화할 수 있는 Partition 단위의 크기를 산정한 후 sub-partition의 개수를 결정
- 결정된 Partition 개수는 Master Table과 Transaction Table과 동일하게 또는 일관성 있게 적용
4.4. Partition Key 선정
1. 성능향상 을 위한 고려
- Data Access 방법에 대한 고려가 되어야 한다. (Index scan vs Full scan)
- Data 분포도에 따른 Scan방법에 대해 고려 가 되어야 한다. (균등 vs 쏠림)
- Data Access, Data 분포도에 따라 Partitioning이 이뤄질 수 있어야 한다.
2. 데이터 관리 용이성 을 위한 고려
- Data의 성격에 따라 Partitioning 되어야 한다.
- 이력 데이터의 경우 생성주기 또는 소멸 주기가 Partition과 일치해야 한다.
4.5. 파티셔닝 방법의 선택 요약
1. Partitioning 대상 선정
- 대량의 건수 및 크기를 보유한 테이블
- 주기적인 데이터 정리(Purge) 또는 새로운 주기 별 데이터 Add가 필요한 테이블
- 대량 데이터 정렬 및 Join이 자주 발생하는 테이블
2. Partitioning 방식의 선정

3. Partitioning Key 선정
- Partitioning Type에 맞는 Key를 파악해야 한다.
- Data Access, Data 분포도에 따라 Partitioning이 이뤄질 수 있어야 한다.
- 이력 데이터의 경우 생성주기 또는 소멸 주기가 Partition과 일치해야 한다.
4. Sub-Partitioning 결정
"구루비 데이터베이스 스터디모임" 에서 2009년에 "이펙티브 오라클" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/3469
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.