이펙티브 오라클 (2009년)
1. AUTOTRACE란
- SELECT, DELETE, UPDATE, INSERT와 같은 SQL DML문이 정상적으로 실행된 후에 자동으로 SQL 옵티마이저에 의해 사용되는 실행계획과 실행 통계에 대한 정보를 얻을 수 있다.
- SQL문의 성능을 모니터링하고 튜닝할 때 사용하는 툴이다.
- 모든 개발자, 환경에 항상 공개되어 있는 것이 장점이다.
2. AUTOTRACE 설치
- sys 계정으로 접속한다.
- plustrce.sql 스크립트를 실행하여 PLUSTRACE롤을 생성한다.
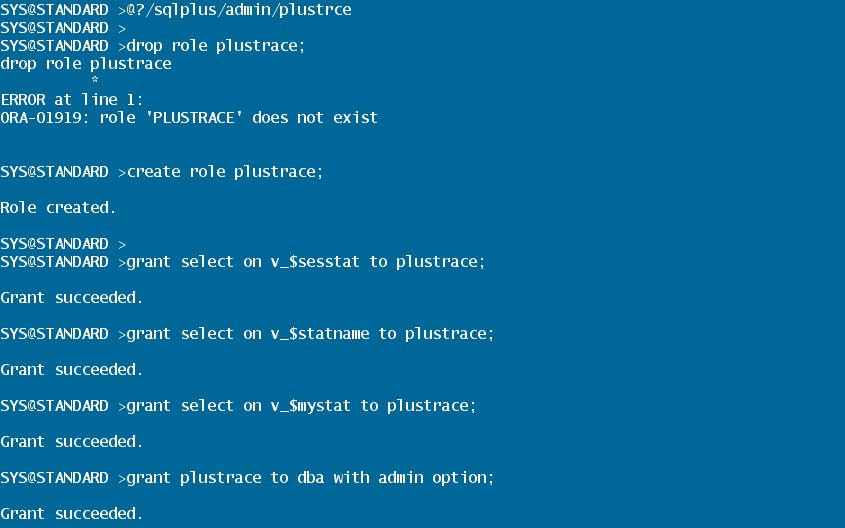
- autotrace를 사용하기 원하는 사용자에게 PLUSTRACE롤을 부여한다.
sqlplus /as sysdba
grant plustrace to hr
3. AUTOTRACE 사용
- AUTOTRACE 시스템 변수를 설정하여 보고서를 제어할 수 있다.

- 가장 마지막의 SET AUTOTRACE TRACEONLY EXPLAIN만이 쿼리를 실제 수행하지 않는다.
- 실행계획을 가장 쉽고 빠르게 확인해 볼 수 있는 방법이다.
4. AUTOTRACE 출력 이해하기
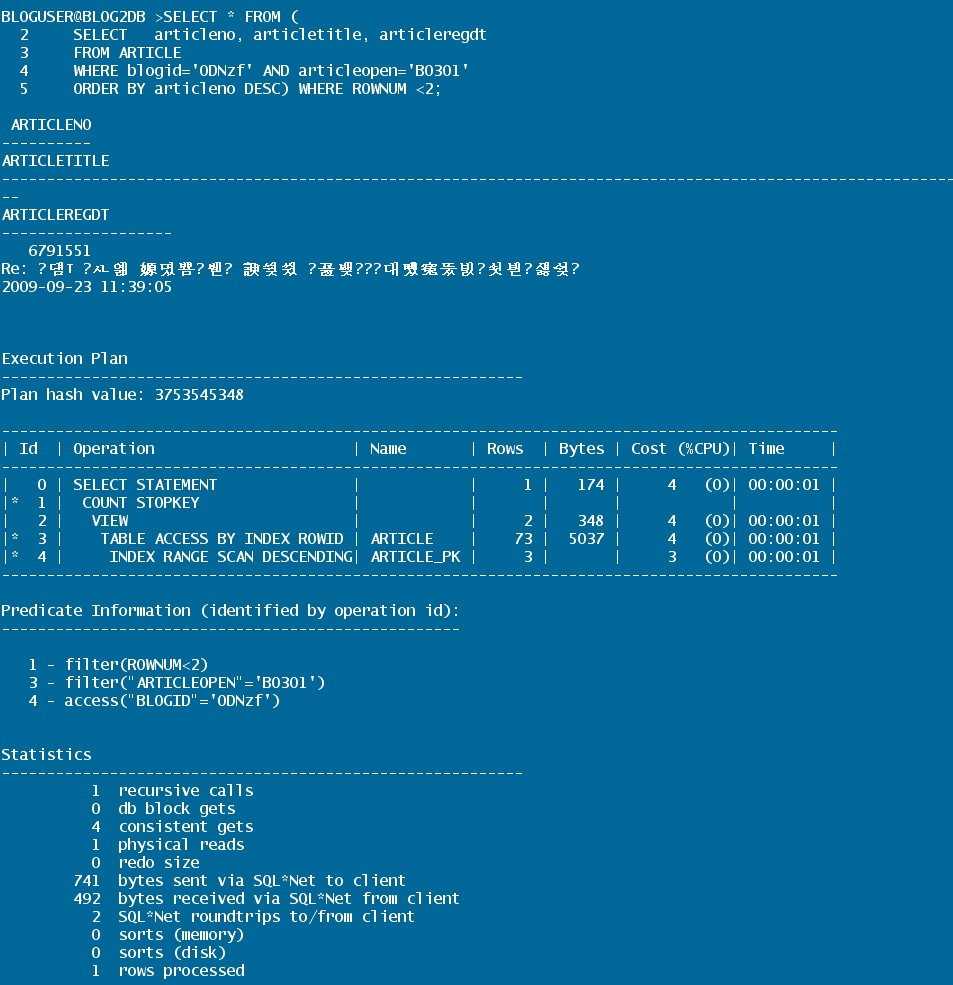
- 비용(Cost) : CBO가 쿼리 계획의 각 단계에 할당한 비용. CBO는 동일한 쿼리에 대해 다양한 실행 경로/계획을 생성함으로써 동가하며 모든 쿼리에 대해 비용을 할당한다.
위의 실행 계획에선 전체 비용이 13인것을 알수 있다.
- 로우수(Rows) : 해당 쿼리 계획 단계에서 나올 것으로 예상되는 행의 수.
- 바이트(Byte) : 계획의 각 단계가 반환할 것으로 예상 되는 데이터의 크기를 바이트로 나타낸 수. 이 수는 행의 수와 행의 예상 길이에 따라 결정된다.
- 시간(Time): 각 단계별 수행 시간을 나타낸다.
- 비용, 카드, 바이트 정보가 나타나지 않는 다면 이는 쿼리가 RBO를 사용하여 실행 되었음을 나타낸다.
4.1. AUTOTRACE 출력에서 무엇을 찾고 있는가?
| 반환된 통계 | 의미 |
|---|---|
| Recursive calls | 사용자의 SQL문을 실행하기 위하여 수행된 SQL 문의 수 |
| Db block gets | 현재 모드(current mode)에서 버퍼 캐시로부터 읽어온 블록의 총 수 |
| Consistent gets | 버퍼 캐시의 블록에 대한 일관된 읽기의 요청 횟수. 일관된 읽기는 언두 정보, 즉 롤백 정보에 대한 읽기를 요구할 수도 있으며 이들 언두에 대한 읽기도 계산된다. |
| Physical reads | 물리적으로 데이터 파일을 읽어 버퍼 캐시에 넣은 횟수 |
| Redo size | 해당 문이 실행되는 동안 생성된 리두의 전체 크기를 바이트 단위로 나타낸 수 |
| Byte sent via SQL*Net to client | 서버로부터 클라이언트에 전송된 총 바이트 수 |
| Byte recevied via SQL*Net from client | 클라이언트로부터 받은 총 바이트 수 |
| SQL*Net roundtrips to/from client | 클라이언트로(부터) 전송된 SQL*Net 메시지의 총 수. 다중 행 결과 집합으로부터 꺼내오기 위한 왕복을 포함한다. |
| Sorts(memory) | 사용자의 세션 메모리(정렬 영역)에서 수행된 정렬 sort_area_size 데이터베이스 매개변수에 의해 제어된다. |
| Sorts(disk) | 사용자의 정렬 영역의 크기를 초과하여 디스크(임시 테이블 영역)를 사용하는 정렬 |
| Rows processed | 수정되거나 select 문으로부터 반환된 행 |
Recursive Calls
- 다른 SQL문의 부작용으로서 실행된 SQL을 가리킨다
- 삽입을 실행하면 쿼리를 실행하는 트리거가 촉발, 쿼리의 파싱, 추가적인 공간 요구, 임시 공간 작업 등...
- 백그라운드에서 수행된 불필요한 추가적인 작업일 가능성이 높으므로 가능한 한 회피되어야 한다.
- 하드 파스(Hard Parses) 처음에 재귀 호출의 수가 높게 나오면 쿼리를 다시 수행해서 이 통계가 여전히 높게 나오는지를 살펴본다. (p.165,166)
- PL/SQL 함수 호출 SQL에서 PL/SQL 함수를 호출하고 이 함수가 직접 다수의 SQL문을 실행하거나 묵시적으로 SQL을 사용하는 USER 같은 내장 함수를 참조하는 경우에도 재귀 호출이 높게 나타난다.(p.167)
- 수정의 부작용 재귀 수정으로 인한 부작용(트리거, 함수 기반의 인덱스 등등)
- 공간 요청 디스크 정렬 또는 공간 확장이 필요할 정도로 테이블이 크게 수정된 경우에 공간 요청을 수용하기 위하여 재귀 SQL 작업이 빈번하게 수행될 수도 있다. 이는 locally manged tablespace에서는 문제가 되지 않으나 dictionary managed tablespace에서는 문제가 될 수 있다.(p.168~171)
- 재귀 SQL은 가능한 한 피해야겠으나 피할 수 없을 때에는 고민하지 말고 수용해야 한다는 것을 염두하라.
- 무작정 이것을 0으로 줄이려고 해서는 안 된다. 전혀 불가능할 뿐만 아니라 실용적이지도 않기 때문이다.
DB block gets 및 Consistent gets
오라클은 두 가지 방식으로 블록을 가져와서 사용한다.
- Current gets 방식에서는 블록을 현재 상태 그대로 읽어 온다.
- dml 문(반드시 해당 블록의 최신 사본만을 갱신해야 한다)이 수행되는 중에 가장 빈번하게 볼 수 있는 것이 이들이다.
- Consistent gets 방식에서는 "읽기 일관성" 모드의 개시 버퍼로부터 블록을 읽어 오며 언두(롤백 세그먼트)의 읽기를 포함 할 수 있다.
- select 문에서 빈번하게 볼 수 있다.
- 논리적 읽기 = DB block gets + Consistent gets
논리적 읽기를 감소하기 위한 방법
- 쿼리 튜닝 인덱스가 항상 좋은 것은 아니며 전체 스캔을 항상 피해야 하는 것이 아니다. CBO를 사용하고 데이터 검색 필요에 따라 데이터 구조에 인덱스를 추가하는 것이다(p.172~176)
- 배열 크기 효과 배열 크기는 서버에 의해 한 번에 인출(또는 삽입, 갱신, 삭제시에 송신)된 행의 수를 말하는데 성능에 지대한 영향을 미칠 수 있다. 너무 작은 수를 주면 Consistents gets 횟수가 과다하게 발생하며 너무 큰 수를 주면 RAM과 cpu 소비가 크다. 책에서는 100-500을 적절한 수로 보고 있다.(p.177~179)
물리적인 읽기(physical reads)
- 쿼리가 얼마나 많은 실제 I/O, 즉 물리적인 I/O를 수행하였는가를 나타낸다.
- 물리적인 읽기는 테이블 또는 인덱스 데이터의 해당 블록이 버퍼 캐시에 가져다 놓는 것을 의미하면 논리적인 I/O는 이 블록을 가져오는 것을 의미한다.
- 대부분의 물리적인 읽기 다음에는 논리적인 I/O가 수반된다.
- 일반적으로 물리적인 I/O는 크게 두 가지로 나뉜다. (p.180~184)
- 데이터 파일로 부터 데이터 읽기 : 인덱스와 테이블 데이터를 인출하기 위하여 데이터 파일을 대상으로 수행된 I/O. 이들 작업 직후에는 캐쉬에 대한 논리적인 I/O가 뒤따른다.
- TEMP로부터 직접 읽기 : 정렬 영역 또는 해시 영역이 메모리 내 전체 정렬/해시를 지원할 만큼 충분하지 않을 때 발생. 일부 데이터를 TEMP에 보냈다가 나중에 이를 다시 읽어온다. 이들 물리적인 읽기는 버퍼 캐시를 우회하므로 논리적인 I/O를 일으키지 않는다.(p.181~183)
- 정렬 영역 크기 설정은 정렬 요청을 만족시키기 위하여 실행 시간에 동적으로 할당되는 메모리의 크기를 제어한다.
- 정렬이 완료되면 이 메모리는 정렬 영역으로 보류된 크기로 줄어들며 쿼리 결과 집합이 소진되면 완전히 반환된다.
- 최적화기는 정렬 영역의 크기가 크다는 사실을 인식함으로써 이 환경에 맞는 쿼리 계획을 생성할 것이다.
- Oracle9i 이상에서는 자동화된 작업 영역 크기 정책을 사용하는 경우 정렬 영역 크기가 전혀 문제가 되지 않는다.
- 정렬 영역, 해시 영역 등을 자동으로 설정한다. 시간에 따라 부하가 증가하거나 감소하기 때문에 실제로 사용된 메모리의 양은 세션의 문마다 달라질 수 있다.
- 사용될 메모리의 양은 세션이 수행하는 모든 문에 대해 동적으로 결정된다.
리두 크기
- SQL이 실행되면서 생성된 리두의 양을 나타내며 대용량 작업의 효율성을 판단하는 데 가장 유용하게 쓰인다.
- 리두는 직접 경로 삽입 또는 CTAS(CREATE TABLE AS SELECT)문에서 가장 빈번하게 나타난다.
- MERGE, UPDATE, DELETE 문에 의해 생성되는 리두의 양은 통재권 밖에 있다.
- 인덱스를 최대한 사용하지 않고 이들 작업을 수행할 경우에는 리두의 양을 줄일 수는 있겠지만 궁극적으로는 이들 비활성 인덱스를 다시 구축하여야 한다.
직접 경로 삽입(APPEND)시 리두 생성하지 않는 경우 (p.185~187)
- NOACHIVELOG 모드.
- NOLOGGING으로 표시된 테이블을 대상으로 작업하고 있는 경우 단순히 테이블을 NOLOGGING 모드로 전환하였다고 이 테이블에 대해 리두가 완전히 없어지는 것은 아니다.
- 삽입, 갱신, 삭제, 병합과 같은 기타 모든 작업에 대해서는 일반적인 방식으로 로그가 기록된다.
NOLOGGING을 설정하고 /*\+ APPEND \*/을 사용하지 말아야 할 이유
- INSERT..VALUES 문에서는 동작하지 않는다.
- NOLOGGING 설정에서는 리두가 생성되지 않기 때문에 데이터 손실의 경우 복구가 어렵다. 반드시 개발자와 DBA가 긴밀하게 협조하여 사용하여야 한다.(반드시 작업 후에는 백업한다.)
- 직접 경로 적재와 마찬가지로 직접 경로 삽입은 테이블의 최고 수위선(HWM) 위에 데이터를 씀으로써 사용 가능 목록에 있는 여유 공간을 모두 무시한다.
- 직접 경로 삽입이 성공적으로 끝나고 동일 트랜잭션에서 해당 테이블로부터 데이터를 읽기 위해서는 반드시 커밋이 수행되어야 한다.
- 한 번에 한 세션만 테이블에 직접 경로 삽입을 수행할 수 있다. 나머지 모든 수정은 차단되어 직렬화가 유발된다.
- (단, 단일 세션 내에서는 병렬 직접 경로 삽입을 수행할 수 있다)
- 리두와 인덱스 작업 NOLOGGING*모드로 설정된 테이블에 INSERT /*+ APPEND \*/ AS SELEECT를 수행하여도 테이블에 인덱스가 설정되었기 때문에 리두와 아카이브는 생성된다. (p.188~189)
데이터 웨어하우스 또는 데이터 마트에 대량 데이터를 적제하는 경우
- 인덱스를 unusable 상태로 설정 : alter index idx_nm unusable;
- 대량 적재시 상태가 unusable인 인덱스를 지나치도록 세션 설정 : alter session set skip_unusable_indexes=true;
- 인덱스 다시 활성화 : alter index idx_nm rebuild nologging;
SQL*Net 통계
- 서버에 전송한 양 (Byte recevied via SQL*Net from client)
- 서버가 전송한 양 (Byte sent via SQL*Net to client)
- 클라이언트에 전송된 데이터를 최소화하려면 필요한 열만을 선택.
- 왕복의 수 (SQL*Net roundtrips to/from client)
- 왕복은 적으면 적을수록 좋고 배열 가져오기 크기가 100과 500 사이일 때 전체적인 성능/메모리 사용도가 가장 좋다.
정렬과 처리된 행
- Sorts(memory)는 전적으로 메모리 내에서 수행된 정렬의 수를 보여준다.
- Sorts(disk) 일부나마 임시 디스크 공간을 필요로 한 정렬의 수를 보여 준다.
- Rows processed는 영향을 받은 행의 수를 보여 준다.
- (SELECT 문으로부터 반환되거나, INSERT, UPDATE, DELETE, MERGE에 의해 수정된 수)
"구루비 데이터베이스 스터디모임" 에서 2009년에 "이펙티브 오라클" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/3462
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.