press x to close
식별자(Identifier)는 데이터 모델에서 매우 중요한 요소다. 식별자는 해당 엔티티의 모든 성격을 좌우하기 때문이다. 그러므로 식별자를 잘못 선정하면 테이블의 정체성이 무너질 수 있다.
특히 유니크 식별자(Unique Indentifier)는 식별자 중에서도 가장 중심이 되는 식별자다.
이 글에서는 식별자 중에서도 가장 중요한 유니크 식별자의 선정 기준을 다양한 각도로 살펴본다.
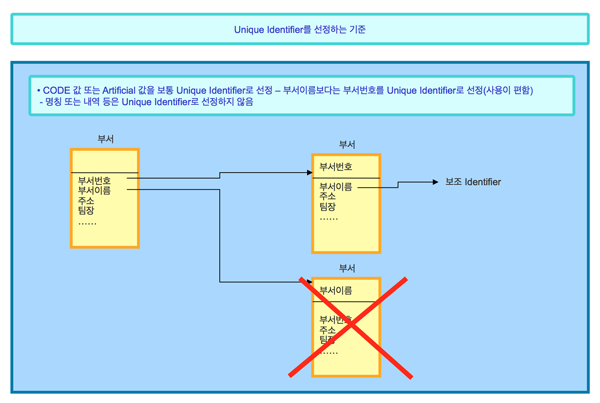
일반적으로 유니크 식별자로는 이름처럼 한글이 저장되는 속성이 아닌 CODE 값이나 Artificial 값이 저장되는 속성을 선정한다.
<그림 1>의 부서 엔티티를 살펴보자. 부서번호 속성과 부서 이름 속성 모두에 유크한 데이터가 저장된다고 가정하자. 이 경우 한글로 저장되는 부서 이름 속성이 아니라 CODE 값으로 데이터가 저장되는 부서번호 속성을 유니크 식별자로 선정하고, 부서 이름 속성을 보조 식별자로 선정한다.
엔티티의 성격상 많은 속성들이 유니크 식별자가 될 수 있는 상황도 생각해볼 수 있다. 이 경우 무엇이 문제가 될 수 있을까?
해당 유니크 식별자를 이용해 엔티티 하나의 데이터를 액세스하면 SQL이 복잡해질 수 있다. 또한 많은 속성을 통해 인덱스를 생성해야 하므로 인덱스 크기도 커질 것이다.
수많은 속성을 유니크 식별자로 선정할 경우 발생할 수 있는 문제점들은 다음과 같다.
① 유니크 식별자를 이용해 한 건의 데이터를 추출할 경우 유니크 식별자가 여러 속성으로 구성돼 있으므로 Where 조건이 증가하고, SQL이 길어져 관리가 어려워질 수 있다.
② 자식 엔티티가 부모 엔티티의 유니크 식별자를 상속받은 상황에서 자신의 속성을 추가하면 계속해서 유니크 식별자가 증가한다.
③ 유니크 식별자는 물리 모델링 시 기본 키(Primary Key)로 구현되므로 인덱스 속성이 증가하게 되며, 인덱스의 크기도 불필요하게 커질 수 있다.
그러므로 여러 개의 속성으로 해당 엔티티의 유니크 식별자를 생성하는 것보다 임의의 유니크 생성자 하나를 생성하는 것이 바람직하다.
이를 인조 유니크 식별자(Artificial Unique Identifier)라고 한다. 이처럼 인조 유니크 식별자를 생성한 경우 기존 유니크 식별자는 보조 식별자로 정의한다.
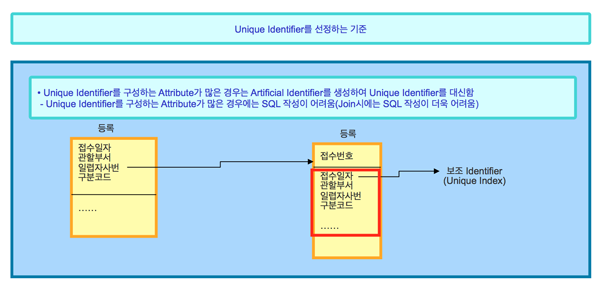
<그림 2>에서 등록 엔티티에서는 4개 속성이 유니크 식별자로 생성된다. 그러므로 접수변호 속성을 인조 유니크 식별자로 구성하는 것이 바람직하다.
물론 기존 유니크 식별자는 보조 식별자로 설정해야 한다. 이는 물리 모델링 시 유니크 인덱스(Unique Index)가 생성될 뿐 아니라 기존의 유니크 식별자는 업무상으로 많이 사용되기 때문이다.
하나의 엔티티에 유니크한 데이터를 저장하는 속성이 여러 개인 경우도 있다. 이처럼 유니크한 데이터를 저장하는 속성이 많은 경우 어떤 속성을 유니크 식별자로 선정해야 할까?
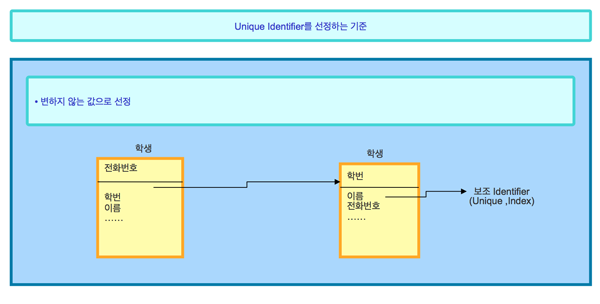
일반적으로 변하는 값은 유니크 식별자로 선정하지 않는다. 예컨대 학생 엔티티에는 유니크한 데이터를 저장하는 속성으로 전화번호 속성과 학번 속성이 있다.
두 속성 모두 유니크한 데이터가 저장된다. 그러나 전화번호 속성은 언제든 값이 바뀔 수 있다. 그렇기 때문에 변치 않는 학번 속성을 유니크 식별자로 선정하고, 값이 변할 수 있는 전화번호 속성은 보조 식별자로 지정한다. 앞서 유니크 식별자는 변하지 않는 값을 저장하는 속성을 선정한다고 설명했다.
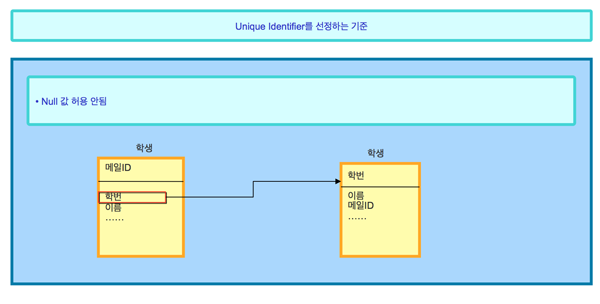
이와 더불어 유니크 식별자는 NULL 값을 허용해서는 안 됨에 주의하자. 해당 엔티티에서 유일한 값을 찾을 수 있는 KEY 값에 NULL이 저장되는 것은 문제 발생의 소지가 커진다. 속성에 NULL 값을 허용하면 다음과 같은 문제가 발생할 수 있다.
① NULL을 허용하는 속성이 NULL 값을 조회할 경우 IS NLL 또는 IS NOT NULL 연산자를 사용해야 하는데, 인덱스에서는 이를 이용할 수 없다.
② NULL로 인해 NVL 함수를 많이 사용하게 되는데, 이로 인해 CPU 사용률이 높아진다.
③ 유니크 식별자뿐 아니라 일반 속성에도 적용되는 주의점인데, 유니크 식별자는 각각의 속성이 NOT NULL을 만족해야만 물리 모델링 시 기본 키(Primary Key)로 생성 가능하다.
지금까지 유니크 식별자를 선정하는 기준에 대해 살펴봤다. 다음 시간에는 다른 식별자를 선정하는 기준에 대해 알아본다






- 강좌 URL : http://www.gurubee.net/lecture/2869
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.