이번 퀴즈로 배워보는 SQL 시간에는 다 대 다(多 對 多) 관계에 있는 두 집합을 연결해 수량을 배분하는 SQL을 작성하는 문제를 풀어본다. 지면 특성상 문제와 정답 그리고 해설이 같이 있다.
진정으로 자신의 SQL 실력을 키우고 싶다면 스스로 문제를 해결한 다음 정답과 해설을 참조하길 바란다. 공부를 잘하는 학생의 문제집은 항상 문제지면의 밑바닥은 까맣지만 정답과 해설지면은 하얗다는 사실을 기억하자.
문제
[리스트 1]은 수주 리스트이고, [표 1]은 수주 정보 테이블입니다. 수주 번호(ID)를 키로 품목(CD), 수량(CNT), 수주 일자(DT) 항목이 있습니다.
- [리스트 1] 수주 리스트
-
CREATE TABLE suju AS SELECT 'A' id, '01' cd, 4 cnt, '20110101' dt FROM dual UNION ALL SELECT 'B', '01', 2, '20110103' FROM dual UNION ALL SELECT 'C', '02', 4, '20110101' FROM dual UNION ALL SELECT 'D', '02', 2, '20110103' FROM dual UNION ALL SELECT 'E', '03', 4, '20110101' FROM dual UNION ALL SELECT 'F', '04', 2, '20110103' FROM dual; SELECT * FROM suju;
- [표 1] 수주 테이블
-
ID CD CNT DT -- ---- ---------- ------------ A 01 4 20110101 B 01 2 20110103 C 02 4 20110101 D 02 2 20110103 E 03 4 20110101 F 04 2 20110103
[리스트 2]는 입고 리스트이며, [표 2]는 입고 정보 테이블입니다. 입고 번호(ID)를 키로 품목(CD), 수량(CNT), 입고 일자(DT) 항목이 있습니다.
- [리스트 2] 입고 리스트
-
CREATE TABLE ipgo AS SELECT 'X' id, '01' cd, 6 cnt, '20110101' dt FROM dual UNION ALL SELECT 'Y', '02', 3, '20110103' FROM dual UNION ALL SELECT 'Z', '02', 3, '20110104' FROM dual UNION ALL SELECT 'P', '02', 4, '20110105' FROM dual UNION ALL SELECT 'Q', '03', 2, '20110102' FROM dual UNION ALL SELECT 'R', '03', 3, '20110103' FROM dual ; SELECT * FROM ipgo;
- [표 2] 입고 테이블
-
ID CD CNT DT -- ---- ---------- ------------- X 01 6 20110101 Y 02 3 20110103 Z 02 3 20110104 P 02 4 20110105 Q 03 2 20110102 R 03 3 20110103
[표 1]의 수주 정보와 [표 2]의 입고 정보를 품목(CD)별로 비교해서, 수주 정보의 수량을 입고 정보의 수량만큼 배분한 결과인 [표 3]과 같은 결과 테이블을 도출하는 결과 쿼리를 작성하세요.
- [표 3] 결과 테이블
-
CD ID CNT ID ---- -- ---------- -- 01 A 4 X 01 B 2 X 02 C 3 Y 02 C 1 Z 02 D 2 Z 03 E 2 Q 03 E 2 R
문제설명
이번 문제는 품목별 수주 수량에 따른 입고 수량을 배분하는 문제입니다.
각 품목별로 수량이 어떻게 배분되는지부터 살펴보겠습니다. 우선 01번 품목에 대한 수주가 A 4개와 B 2개로 2건이고, 입고가 X 6개로 1건입니다. 따라서 입고 수량 6개가 수주 수량에 맞게 4개와 2개로 나눠지는 것입니다.
02번 품목에 대한 수주가 C 4개와 D 2개 2건이고, 입고가 Y 3개, Z 3개, P 4개로 3건입니다. C 4개에 대해 Y 3개, Z 1개가 연결되고 나머지 Z 2개가 D 2개와 연결됩니다. P 4개는 연결될 수 있는 주 정보가 없어 제외됩니다.
03번 품목에 대한 수주가 E 4개로 1건이고, 입고가 Q 2개와 R 3개로 2건입니다. E 4개가 Q 2개와 R 2개로 나뉘고, 남은 R 1개는 제외됩니다. 이와 같이 수주 수량과 입고 수량을 품목별로 비교해 재배분하는 것이 오늘의 문제입니다.
정답
문제를 스스로 해결해 보셨나요? 이제 정답을 알아보겠습니다.
- [리스트 3] 정답 리스트
SELECT a.cd
, a.id
, LEAST( a.cnt
, b.cnt
, a.s_cnt - b.s_cnt + b.cnt
, b.s_cnt - a.s_cnt + a.cnt
) cnt
, b.id
FROM (SELECT a.*
, SUM(cnt) OVER(PARTITION BY cd ORDER BY dt) s_cnt
FROM suju a
) a
, (SELECT b.*
, SUM(cnt) OVER(PARTITION BY cd ORDER BY dt) s_cnt
FROM ipgo b
) b
WHERE a.cd = b.cd
AND a.s_cnt > b.s_cnt - b.cnt
AND b.s_cnt > a.s_cnt - a.cnt
ORDER BY a.cd, a.dt, b.dt
;
어떤가요? 여러분이 만들어본 리스트와 같은가요? 틀렸다고 좌절할 필요는 없답니다. 첫 술에 배부를 순 없는 것이니까요. 해설을 꼼꼼히 보고 자신이 잘못한 점을 비교해 보는 것이 더 중요합니다.
해설
차근차근 정답에 접근해 볼까요? 먼저 두 집합의 연결고리는 품목(CD)입니다. 하지만 이 관계는 다 대 다 관계입니다. 다 대 다 관계는 원치 않는 결과가 중복되는 상황이 발생할 수밖에 없습니다.
이렇게 품목만으로는 연결고리가 부족하므로 차선책으로 수량을 생각해볼 수 있는데, 수량은 서로 달라서 이퀄 비교도 안 되고 어떻게 연결해야 할지 막막하기만 합니다. 하지만 수주 정보를 자세히 보면 시간의 흐름에 따라, 즉 날짜별로 수량이 추가됨을 알 수 있습니다.
이 날짜별로 증가하는 수량 추이를 이용하면 어떨까요?
- [리스트 4] 수주량 증가 내역 쿼리
-
SELECT a.* , SUM(cnt) OVER(PARTITION BY cd ORDER BY dt) - cnt b_cnt , SUM(cnt) OVER(PARTITION BY cd ORDER BY dt) s_cnt FROM suju a ;
- [표 4] 수주량 증가 내역 결과
-
ID CD CNT DT B_CNT S_CNT -- ---- ---------- ---------------- ---------- ---------- A 01 4 20110101 0 4 B 01 2 20110103 4 6 C 02 4 20110101 0 4 D 02 2 20110103 4 6 E 03 4 20110101 0 4 F 04 2 20110103 0 2
[리스트 4]의 쿼리를 이용해 [표 4]와 같은 결과를 얻었습니다. 분석함수를 이용해 품목별 날짜순으로 수량을 누적 합산했습니다(S_CNT). 그리고 그 결과에서 현재 행의 수주량을 차감하면 직전 수주량을 구할 수 있습니다(B_CNT).
[표 4]의 첫 번째 행 자료를 보면 수주량이 0개에서 4개로 늘어난 것이 확인되네요. 그리고 <표 4>의 두 번째 행 자료를 보면 수주량이 4개에서 6개로 늘어난 것이 확인? 범위 조건으로 이용할 수 있습니다.
비교를 위해 입고량 증가 내역도 한번 확인해 보죠.
- [리스트 5] 입고량 증가 내역 쿼리
-
SELECT b.* , SUM(cnt) OVER(PARTITION BY cd ORDER BY dt) - cnt b_cnt , SUM(cnt) OVER(PARTITION BY cd ORDER BY dt) s_cnt FROM ipgo b ;
- [표 5] 입고량 증가 내역 결과
-
ID CD CNT DT B_CNT S_CNT -- ---- ---------- ---------------- ---------- ---------- X 01 6 20110101 0 6 Y 02 3 20110103 0 3 Z 02 3 20110104 3 6 P 02 4 20110105 6 10 Q 03 2 20110102 0 2 R 03 3 20110103 2 5
[리스트 5]의 쿼리를 이용해 [표 5]의 결과를 얻었습니다. 마찬가지로 입고량을 시작 수량 B_CNT와 종료수량 S_CNT 범위로 표시한 것입니다. 이제는 [표 4]와 [표 5]를 연결하는 조건을 어떻게 작성해야 할지 고민할 차례입니다.
먼저 범위 구간을 가진 두 집합을 비교해 범위가 겹치는 부분을 찾아내야 합니다. 그러나 여러 가지 경우를 생각해야 하고 이를 만족시키려면 조건은 까다롭고, 복잡해지며, 난해해지기 일쑤입니다.
하지만 잘 생각해보면 그리 까다로운 조건은 아닙니다. 시작점과 끝점을 서로 교차해 비교하면 간단하게 해결되니까요. 두 집합을 A와 B로 표현했을 때, 겹치는 구간에 대한 조건은 다음과 같습니다.
- - A의 시작점은 반드시 B의 종료점보다 작다.
- - A의 종료점은 반드시 B의 시작점보다 크다.
- 이를 앞서 구한 항목들과 접목시켜보면 조건절은 다음과 같습니다.
AND a.s_cnt > b.b_cnt -- A의 종료점은 반드시 B의 시작점보다 크다. AND b.s_cnt > a.b_cnt -- A의 시작점은 반드시 B의 종료점보다 작다.
자, 이제 두 집합의 연결고리를 찾았습니다. 어서 쿼리를 완성해 봅시다.
- [리스트 6] 범위 조건으로 연결하는 쿼리
-
SELECT a.cd , a.id id_a , a.cnt cnt_a , a.s_cnt + a.cnt 시작점a , a.s_cnt 종료점a , b.s_cnt + b.cnt 시작점b , b.s_cnt 종료점b , b.cnt cnt_b , b.id id_b FROM (SELECT a.* , SUM(cnt) OVER(PARTITION BY cd ORDER BY dt) s_cnt FROM suju a ) a , (SELECT b.* , SUM(cnt) OVER(PARTITION BY cd ORDER BY dt) s_cnt FROM ipgo b ) b WHERE a.cd = b.cd AND a.s_cnt > b.s_cnt - b.cnt AND b.s_cnt > a.s_cnt - a.cnt ORDER BY a.cd, a.dt, b.dt ;
- [표 6] 범위 조건으로 연결한 결과
-
CD ID CNT_A 시작점A 종료점A 시작점B 종료점B CNT_B ID ---- -- ---------- ---------- ---------- ---------- ---------- ---------- -- 01 A 4 8 4 12 6 6 X 01 B 2 8 6 12 6 6 X 02 C 4 8 4 6 3 3 Y 02 C 4 8 4 9 6 3 Z 02 D 2 8 6 9 6 3 Z 03 E 4 8 4 4 2 2 Q 03 E 4 8 4 8 5 3 R
[리스트 6]의 쿼리를 이용해 [표 6]의 결과를 얻었습니다. [리스트 4]와 [리스트 5]에서 구한 시작점인 B_CNT 항목은 별도로 생성하지 않고 S_CNT - CNT이라는 계산식으로 대체했습니다. 동일한 의미니까요.
[표 6]의 결과를 보면 [표 3]의 결과 테이블 건수와 순서가 정확하게 일치합니다. 즉, 연결 조건을 완성한 것입니다. 다만 수량에 대한 배분 부분만 완성하지 못한 상태입니다. 구간이 겹치는 여러 가지 유형별로 수량을 배분하는 방법을 지금부터 살펴보겠습니다.
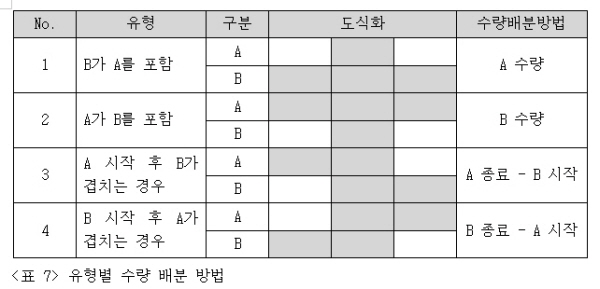
[표 7]을 보면 구간이 겹치는 유형은 크게 네 가지로 구분할 수 있습니다. 이렇게 네 가지 유형에 대한 수량을 모두 계산한 다음, 이중 가장 작은 값 하나를 선택하는 방법으로 최종 SQL을 완성해 보죠.
- 1. B가 A를 포함하는 경우엔 A의 수량으로 배분
- 2. A가 B를 포함하는 경우엔 B의 수량으로 배분
- 3. A가 먼저 시작해 B가 시작된 후 A가 종료되는 경우에는 A의 종료 수량에서 B의 시작 수량을 차감
- 4. B가 먼저 시작해 A가 시작된 후 B가 종료되는 경우에는 B의 종료 수량에서 A의 시작수량을 차감
- [리스트 7] 유형별 계산 결과 적용
-
, LEAST( a.cnt -- 1번 유형 , b.cnt -- 2번 유형 , a.s_cnt - (b.s_cnt + b.cnt) -- 3번 유형 , b.s_cnt - (a.s_cnt + a.cnt) -- 4번 유형 ) cnt
유형별 수량을 각각 계산한 뒤 LEAST 함수를 이용해 가장 작은 값을 취하면 수량 배분이 완성됩니다. 이렇게 수량 배분까지 적용하면 정답 리스트가 완성됩니다.
이번 퀴즈로 배우는 SQL 시간에는 다 대 다 집합을 서로 연결해 결과를 도출해내는 방법을 살펴봤습니다. 그 도출과정이 만만치 않았는데요. 순차적으로 되짚어보겠습니다.
먼저 분석함수를 이용해 추가되는 수량에 대한 누적합계를 구하고, 그 합계를 이용해 수량에 대한 구간정보인 시작부터 종료까지를 만들었습니다. 이렇게 만든 시작과 종료를 서로 교차해 비교하고 조인한 다음, 끝으로 도출한 조인 결과에 유형별 계산 및 LEAST 함수를 사용해 수량을 배분하는 방법까지 살펴봤습니다.
앞으로도 이런 복잡한 과정을 차근차근 밟아나가면서 문제를 해결하는 능력을 키워야 되겠습니다.
- 강좌 URL : https://www.gurubee.net/lecture/2837
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.