press x to close
Entity는 데이터 모델의 중요한 요소다. 따라서 이와 같은 Entity를 어떻게 구성하는지에 따라 해당 시스템의 앞날이 좌우된다. 이번 시간에는 데이터 모델링에서 Entity의 분할에 대해 살펴보자. Entity의 분할이 반드시 필요함을 이해하면서, 어떤 방식으로의 분할이 있는지를 확인해 보자.
Subset에 의한 분할은 Data만 분리하는 것을 의미한다. 예를 들어 계좌 Entity에서 법인 계좌와 개인 계좌 Data를 분리한다고 가정하자.
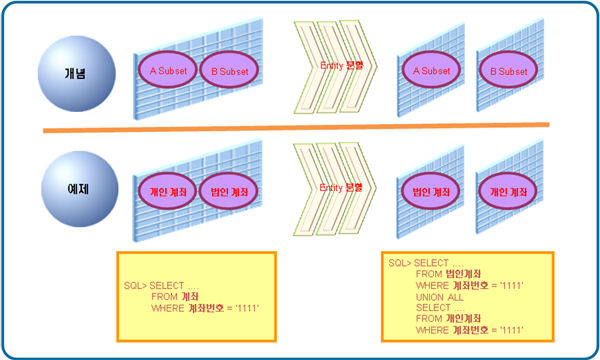
그렇다면 [그림1]의 예제와 같이 법인 계좌 Entity와 개인 계좌 Entity를 도출할 수 있을 것이다. 이와 같이 하나의 Entity에 동일한 형태의 Data가 구분돼 저장되어 있을 경우 Subset에 의한 분할을 고려할 수 있게 된다.
이와 같이 Subset에 의한 Entity 분할을 수행한다면 하나의 계좌번호 값에 대해 조회를 수행하는 SQL이 달라질 수 있다. 보통의 경우에는 Entity 분할을 수행하게 되면 해당 Entity를 액세스하는 SQL은 복잡해질 수 있다.
물론 계좌번호 자체로 법인 계좌인지 아닌지를 확인할 수 있다면 굳이 UNION ALL을 이용할 필요 없이 애플리케이션에서 해당 Entity만 액세스하면 될 것이다. 이와 같다면 Entity 분할도 동일해진다. Entity 분할을 통해 [표 1]과 같은 현상이 발생할 수 있다.
| 항목 | 통합 Entity | Subset 분리 Entity | 비고 |
|---|---|---|---|
| 온라인 처리 | 유리 | 불리 | - 통합 조회 (SQL 복잡/성능 저하 가능) |
| 배치 처리 | 불리 | 유리 | - Subset별로 배치 처리할 경우 (Partition Architecture로 해결 가능) |
| 업무 유연성 (Subset 별) | 불리 | 유리 | - 업무 변경으로 Attribute 추가 시 |
| 업무 유연성 (전체) | 유리 | 불리 | - Entity 추가 생성 및 Application 변경 필요(Subset 분리) |
| 관리 | 불리 | 유리 | - 개별 작업 가능 |
| 저장 공간 | - | - | |
| Data 정합성 | - | - | |
| 업무분석 | 불리 | 유리 | - Entity Name으로 구분가능 |
결국, Subset에 의한 Entity 분리는 통합 Entity와 비교해 장단점이 존재하며 업무 성격 및 해당 Entity에 대한 액세스 유형을 파악하고 그에 맞게 선택해 사용해야 할 것이다.
근본 Entity로의 분할이란 코드화되어 있지 않은 중복된 Code 값을 분리해 근본 Entity로 도출하는 것을 말한다.
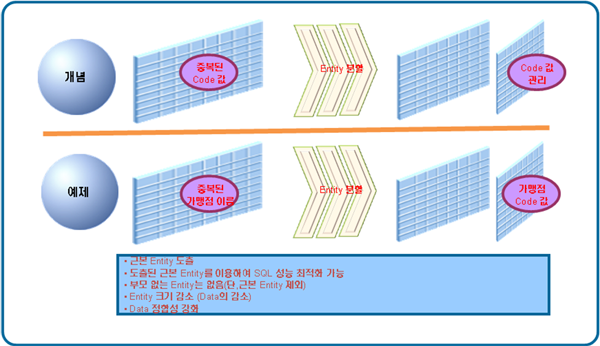
1 2 3 4 | SELECT * FROM 거래 WHERE 거래일자 = '20080330' AND 가맹점_이름 IN (SELECT 가맹점_이름 FROM 가맹점); |
앞서 살펴본 것처럼 Entity는 여러 가지 형태로 분할할 수 있다. Entity 분할은 하나의 Entity를 작은 Entity로 분리하는 것을 의미하며, 이를 수행하는 이유는 다음과 같다.






- 강좌 URL : http://www.gurubee.net/lecture/2735
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.