press x to close
SELECT ord_dept, ordqty * 1000
FROM order
WHERE ord_date like '2005%'
ORDER BY ord_dept desc
;
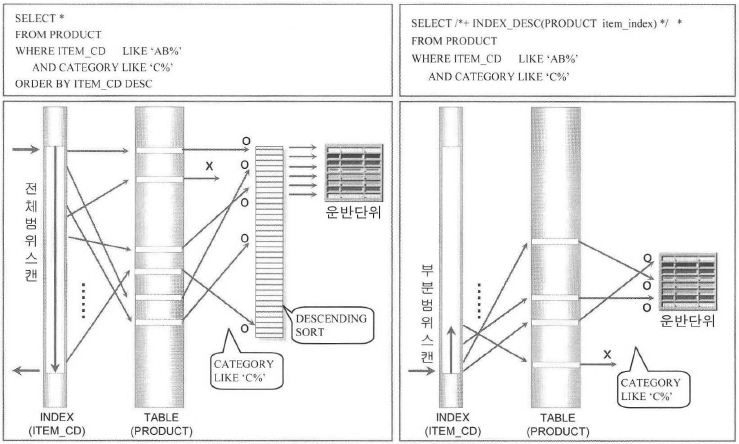
-- ORD_DATE 의 처리범위가 넓지 않다면 가장 양호한 액세스 경로가 되겠지만, 처리범위가 넓다면 부담이됨.
# 예측 실행계획
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)|
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96929 | 5774K| | 2120 (1)|
| 1 | SORT ORDER BY | | 96929 | 5774K| 13M| 2120 (1)|
| 2 | TABLE ACCESS BY INDEX ROWID| ORDER_T | 96929 | 5774K| | 675 (1)|
|* 3 | INDEX RANGE SCAN | IDX_ORDER_ORD_DATE | 96929 | | | 272 (2)|
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("ORD_DATE" LIKE '2005%')
filter("ORD_DATE" LIKE '2005%')
SELECT /*+ INDEX_DESC(a ord_dept_index) */
ord_dept, ordqty * 1000
FROM order a
WHERE ord_date like '2005%'
AND ord_dept > ' '
;
-- AND ord_dept > ' ' 을 추가함으로써 이 SQL 은 액세스를 주관하는 컬럼과 'ORDER BY'할 컬럼이 같아짐.
-- 속도향상 원리 '액세스 주관 컬럼의 처리범위가 넓어도 다른 조건의 처리범위도 같이 넓으면 빠르다'는
원리에 의해 아주 빠른 수행속도를 얻을수 있음.
-- 힌트를 통해 액세스 주관 컬럼을 ord_dept_index 로 지정, 원래의 조건은 검증 조건으로 바꾸어 부분범위 처리로 유도함.
# 예측 실행계획
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96929 | 5774K| 213K (1)|
|* 1 | TABLE ACCESS BY INDEX ROWID | ORDER_T | 96929 | 5774K| 213K (1)|
|* 2 | INDEX RANGE SCAN DESCENDING| IDX_ORDER_T_ORD_DEPT | 1034K| | 2005 (2)|
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ORD_DATE" LIKE '2005%')
2 - access("ORD_DEPT">' ')
filter("ORD_DEPT">' ')
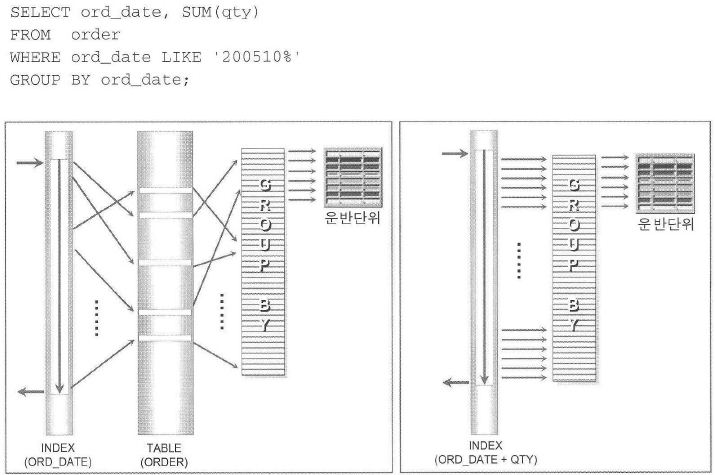
SELECT ord_date, SUM(ordqty)
FROM order
WHERE ord_date LIKE '2005%'
GROUP BY ord_date
;
# 예측 실행계획
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96929 | 3691K| 675 (1)|
| 1 | SORT GROUP BY NOSORT | | 96929 | 3691K| 675 (1)|
| 2 | TABLE ACCESS BY INDEX ROWID| ORDER_T | 96929 | 3691K| 675 (1)|
|* 3 | INDEX RANGE SCAN | IDX_ORDER_ORD_DATE | 96929 | | 272 (2)|
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("ORD_DATE" LIKE '2005%')
filter("ORD_DATE" LIKE '2005%')
# 예측 실행계획 : 결합인덱스 생성후 (ORD_DATE + QTY)
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 96929 | 3691K| 326 (1)|
| 1 | SORT GROUP BY NOSORT| | 96929 | 3691K| 326 (1)|
|* 2 | INDEX RANGE SCAN | IDX_ORDER_ORD_DATE_QTY | 96929 | 3691K| 326 (1)|
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ORD_DATE" LIKE '2005%')
filter("ORD_DATE" LIKE '2005%')
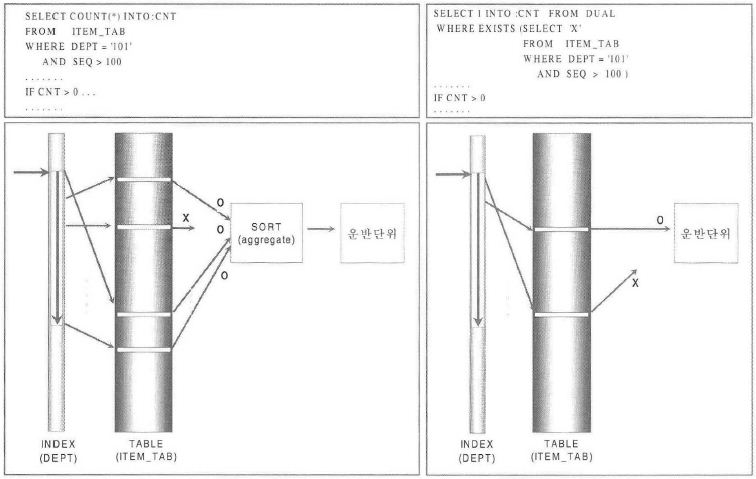
SELECT ord_dept, COUNT(*)
FROM order
WHERE ord_date LIKE '200510%'
GROUP BY ord_dept
;
# 예측 실행계획
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 48 | 2304 | 17 (6)|
| 1 | HASH GROUP BY | | 48 | 2304 | 17 (6)|
| 2 | TABLE ACCESS BY INDEX ROWID| ORDER_T | 48 | 2304 | 16 (0)|
|* 3 | INDEX RANGE SCAN | IDX_ORDER_ORD_DATE_AGENT_CD | 48 | | 3 (0)|
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("ORD_DATE" LIKE '200510%')
filter("ORD_DATE" LIKE '200510%')
-- 'ORD_DATE + AGENT_CD' 인덱스로 전체범위를 스캔하여 랜덤으로 테이블을 액세스하고, GROUP BY 를 한 후 결과를 추출.
SELECT agent_cd, COUNT(*)
FROM order
WHERE ord_date LIKE '200510%'
GROUP BY agent_cd
;
# 예측 실행계획
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 48 | 1536 | 4 (25)|
| 1 | HASH GROUP BY | | 48 | 1536 | 4 (25)|
|* 2 | INDEX RANGE SCAN| IDX_ORDER_ORD_DATE_AGENT_CD | 48 | 1536 | 3 (0)|
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ORD_DATE" LIKE '200510%')
filter("ORD_DATE" LIKE '200510%')
-- 이 SQL 은 'ORD_DATE + AGENT_CD' 인덱스만 사용하는 실행계획을 수립하므로 훨씬 빠른 수행속도를 얻을 수 있음.
CREATE SEQUENCE empno_seq ------------------- 시퀀스 명
INCREMENT BY 1 ------------------- 증가 단위
START WITH 1 ------------------- 시작 숫자
MAXVALUE 100000000 ------------------- 최대값 제한
NOCYCLE ------------------- 순환 여부
CACHE 20 ------------------- 메모리 확보 단위
SELECT empno_seq.CURRVAL FROM DUAL ;
INSERT INTO EMP (empno, ename, job, hiredate, sal)
VALUES (empno_seq.NEXTVAL, 'James Dean', 'MANAGER', '2011-08-14', 30000000) ;
UPDATE EMP
SET empno = empno_seq.NEXTVAL
WHERE empno = 10001 ;
SELECT ord_dept, ord_date, custno
FROM order
WHERE ord_date like '2005%'
MINUS
SELECT ord_dept, ord_date, '12541'
FROM sales
WHERE custno = '12541';
SELECT ord_dept, ord_date, custno
FROM order x
WHERE ord_date like '2005%'
AND NOT EXISTS (SELECT * FROM sales y
WHERE y.ord_dept = x.ord_dept
AND y.ord_date = x.ord_date
AND y.custno = '12541'
) ;
Execution Plan
------------------------------------------------------------
SELECT STATEMENT
COUNT (STOPKEY)
TABLE ACCESS (FULL) OF 'PRODUCT'
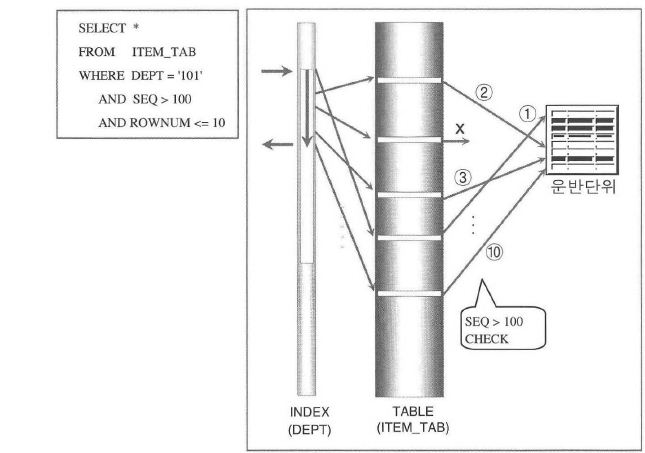
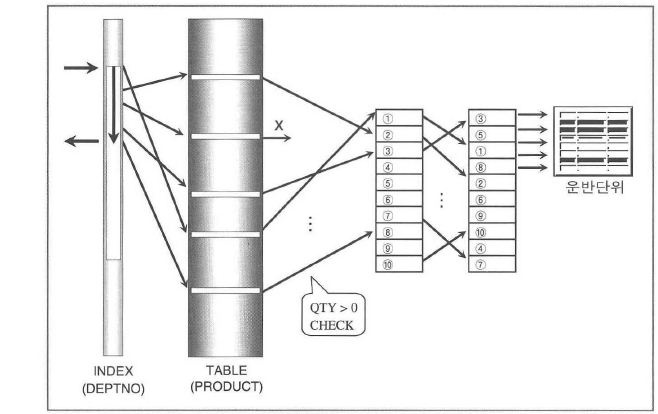
SELECT ROWNUM, item_cd, category_cd, ......
FROM product
WHERE deptno like '120%'
AND qty > 0
AND ROWNUM <= 10
ORDER BY item_cd
;
SELECT ROWNUM, item_cd, category_cd, ......
FROM (SELECT *
FROM product
WHERE deptno like '120%'
AND qty > 0
ORDER BY item_cd
)
WHERE ROWNUM <= 10
;
-- 이 방법은 인라인뷰 내에 있는 처리는 전체범위로 수행되므로
-- 불필요한 액세스가 많이 발생할 수 있으므로 주의하여야 함.
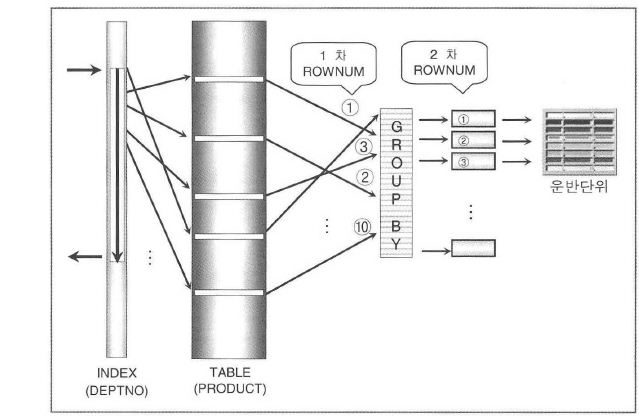
CREATE VIEW PROD_VIEW (deptno, totqty)
AS SELECT deptno, sum(qty)
FROM product
GROUP BY deptno
;
-- 뷰는 자료사전(Data Dictionary)에 SQL 문장이 저장되어 있다가 SQL 을 수행하는 순간,
-- 뷰의 SQL(뷰 쿼리)과 수행시킨 SQL(액세스 쿼리)을 합성(Merge)하여 실행계획을 수립.
-- 아래 SQL 에서는 뷰를 이용해 ROWNUM 을 요구
SELECT ROWNUM, deptno, totqty
FROM PROD_VIEW
WHERE deptno like '120%'
AND ROWNUM <= 10
;
-- 뷰를 생성한 SQL 에는 조건절이 전혀 없었지만 SQL 을 실행하면
-- 액세스 쿼리가 뷰 쿼리로 합성되어 다음과 같은 SQL 이 내부적으로 만들어져서 수행됨.
SELECT ROWNUM, dept, totqty
FROM (SELECT deptno, sum(qty) totqty
FROM product
WHERE deptno like '120%'
GROUP BY deptno
)
WHERE ROWNUM <= 10
;
-- GROUP BY 를 수행한 결과는 내부적으로 저장이 되며 이때 ROWNUM 도 같이 생성됨.
SELECT a.dept_name, b.empno, b.emp_name, c.sal_ym, c.sal_tot
FROM department a, employee b, salary c
WHERE b.deptno = a.deptno
AND c.empno = b.empno
AND a.location = 'SEOUL'
AND b.job = 'MANAGER'
AND c.sal_ym = '200512'
ORDER BY a.dept_name, b.hire_date, c.sal_ym
;
SELECT /*+ ORDERD, USE_NL(x y) */
a.dept_name, b.empno, b.emp_name, c.sal_ym, c.sal_tot
FROM (SELECT a.dept_name, b.hire_date, b.empno, b.emp_name
FROM DEPT a, EMPLOYEE b
WHERE b.deptno = a.deptno
AND a.location = 'SEOUL'
AND b.job = 'MANAGER'
ORDER BY a.dept_name, b.hire_date ) x, SALARY y
WHERE y.empno = x.empno
AND y.sal_ym = '200512'
;
SELECT a.product_cd, product_name, avg_stock
FROM PRODUCT a,
(SELECT product_cd, SUM(stock_gty) / (:b2 - :b1) avg_stock
FROM PROD_STOCK
WHERE stock_date between :b1 and :b2
GROUP BY product_cd ) b
WHERE b.product_cd = a.product_cd
AND a.category_cd = '20'
;
CREATE or REPLACE FUNCTION GET_AVG_STOCK
( v_start_date in date,
v_end_date in date,
v_product_cd in varchar2
)
RETURN number IS
RET_VAL number(14) ;
BEGIN
SELECT SUM(stock_qty) / (v_start_date - v_end_date) ) into RET_VAL
FROM PROD_STOCK
WHERE product_cd = v_product_cd
AND stock_date between v_start_date and v_end_date ;
RETURN RET_VAL ;
END GET_AVG_STOCK ;
SELECT product_cd, product_name,
GET_AVG_STICJ (product_cd, :b1, :b2) avg_stock
FROM PRODUCT
WHERE category_cd = '20'
;
SELECT y.cust_no, y.cust_name, x.bill_tot, ............
FROM ( SELECT a.cust_no, sum(bill_amt) bill_tot
FROM account a, charge b
WHERE a.acct_no = b.acct_no
AND b.bill_cd = 'FEE'
AND b.bill_ym = between :b1 and :b2
GROUP BY a.cust_no
HAVING sum(b.bill_amt) >= 1000000 ) x, customer y
WHERE y.cust_no = x.cust_no
AND y.cust_status = 'ARR'
AND ROWNUM <= 30
;
CREATE or REPLACE FUNCTION CUST_ARR_FEE_FUNC
( v_costno in varchar2,
v_start_ym in varchar2,
v_end_ym in varchar2
)
RETURN number IS
RET_VAL number(14) ;
BEGIN
SELECT sum(bill_amt) into RET_VAL
FROM account a, charge b
WHERE a.acct_no = b.acct_no
AND a.cust_no = v_cust_no
AND b.bill_cd = 'FEE'
AND b.bill_ym between v_start_ym and v_end_ym ;
RETURN RET_VAL ;
END CUST_ARR_FEE_FUNC ;
SELECT CUST_NO, CUST_NAME, CUST_ARR_FEE_FUNC(cust_no, :b1, :b2), ................
FROM CUSTOMER
WHERE CUST_STATUS = 'ARR'
AND CUST_ARR_FEE_FUNC(cust_no, :b1, :b2) >= 1000000
AND ROWNUM <= 30
;
SELECT cust_no, cust_name, bill_tot, .........
FROM ( SELECT ROWNUM, cust_no, cust_name,
CUST_ARR_FEE_FUNC(cust_no, :b1, :b2) bill_tot, ...............
FROM customer
WHERE cust_status = 'ARR' )
WHERE bill_tot >= 1000000
AND ROWNUM <= 30
;
-- 이 SQL 의 실행계획을 보면 몇 가지 특이한 점을 발견할 수 있다.
Execution Plan
----------------------------------------------------------------------
SELECT STATEMENT
COUNT (STOPKEY)
VIEW --------------------------------------- (b)
COUNT --------------------------------------- (a)
TABLE ACCESS (BY ROWID) OF 'CUSTOMER'
INDEX (RANGE SCAN) OF 'CUST_STATUS_IDX'
- 강좌 URL : http://www.gurubee.net/lecture/2621
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.