press x to close
| 구분 | Ordinary | Index-Organized Table |
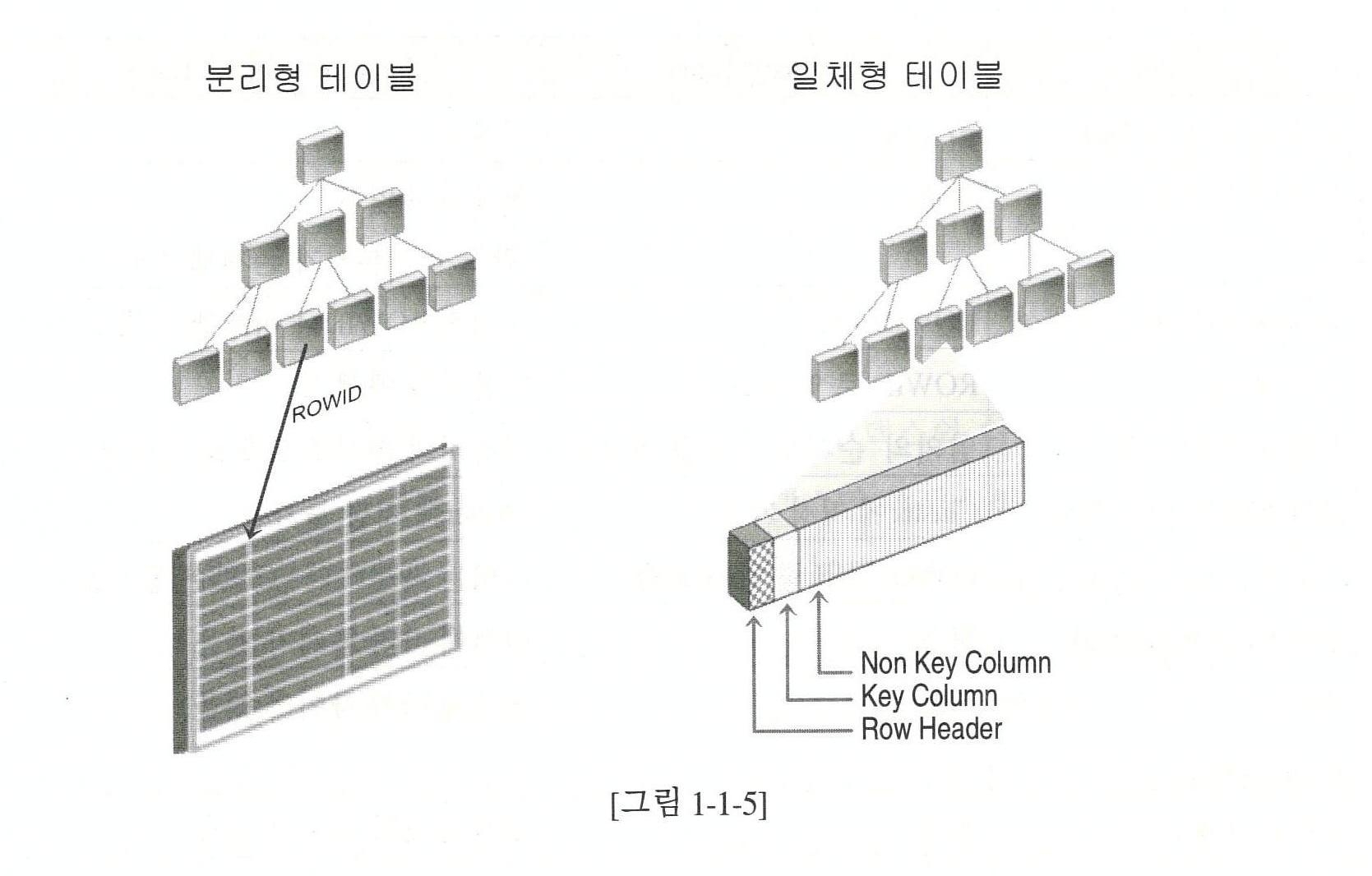
| 로우의 유일 식별자 | ROWID | 기본키 |
| 기본키 미지정 | 허용 | 허용하지 않음(반드시 기본키가 존재해야함) |
| Secondary인덱스의 생성 | ROWID사용 | 논리적 ROWID나 비트맵 인덱스 |
| 로우 액세스 | ROWID로 액세스 | 기본키로 액세스 |
| 전체테이블 스캔 | 임의의 순서로 로우를 리턴함 | 기본키의 순서로 로우를 리턴함 |
| 클러스터링 가능여부 | CLuster에 저장 가능 | Cluster에 저장이 불가능 |
| LONG,LONG RAW,LOB | LONG,LOB중 하나포함 | LOB는 가능하나 LONG은 불가능 |
| 분산(Distributed) SQL | 허용 | 버전에 따라 차이가 있음 |
| 데이터 이중화 (Replication) | 허용 | 버전에 따라 차이가 있음 |
| 파티션 적용 | 허용 | 버전에 따라 차이가 있음 |
| 병렬처리 | 허용 | 버전에 따라 차이가 있음 CTAS를 통한 병렬 데이터 로딩 파티션 및 일반 IOT의 병렬 고속 전체스캔(FFS) 파티션 IOT의 병렬 인덱스 스캔 |
 |
 |
 |
- 강좌 URL : http://www.gurubee.net/lecture/2601
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.