press x to close
by 마농 정규표현식 REGEXP_REPLACE REGEXP_SUBSTR INSTR SUBSTR LPAD IP정렬 [2012.06.04]
이번 퀴즈로 배워보는 SQL 시간에는 IP 목록을 정렬하는 쿼리를 어떻게 작성하는지에 대해 알아본다.
지면 특성상 문제와 정답 그리고 해설이 같이 있다. 진정으로 자신의 SQL 실력을 키우고 싶다면 스스로 문제를 해결 한 후 정답과 해설을 참조하길 바란다.
공부를 잘 하는 학생의 문제집은 항상 문제지면의 밑바닥은 까맣지만 정답과 해설지면은 하얗다는 사실을 잊지 말자.
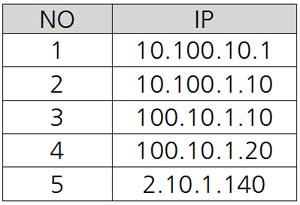
다음과 같은 IP 목록을 가진 테이블([그림 1] 참조)에서 IP 순서대로 정렬하여 결과를 출력하는 쿼리를 작성하세요.
[리스트1]의 쿼리를 실행하면 [그림 1]의 원본 테이블 자료가 조회됩니다.
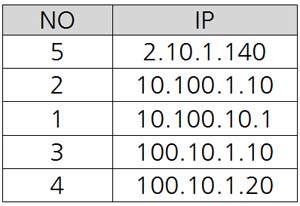
[리스트1]의 WITH문을 이용하여 [그림 2]의 결과 테이블 자료가 조회되는 쿼리를 작성하세요.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | -- 원본리스트 테이블 생성CREATE TABLE T ASSELECT '10.100.10.1' ip FROM dualUNION ALL SELECT '10.100.1.10' FROM dualUNION ALL SELECT '100.10.1.10' FROM dualUNION ALL SELECT '100.10.1.20' FROM dualUNION ALL SELECT '2.10.1.140' FROM dual;-- 데이터 조회SELECT ROWNUM rn , ip FROM t;-- 조회 결과 RN IP------ ----------- 1 10.100.10.1 2 10.100.1.10 3 100.10.1.10 4 100.10.1.20 5 2.10.1.140 |
문제를 스스로 해결해 보셨나요? 이제 정답을 알아보겠습니다.
1 2 3 4 5 | SELECT ROWNUM rn , ip FROM t ORDER BY REGEXP_REPLACE(REPLACE('.'||ip, '.', '.00'), '([^.]{3}(\.|$))|.', '\1'); |
어떤가요? 여러분이 만들어본 리스트와 같은가요? 틀렸다고 좌절할 필요는 없답니다. 첫 술에 배부를 순 없는 것이니까요. 해설을 꼼꼼히 보고 자신이 잘못한 점을 비교해 보는 것이 더 중요합니다.
오라클 10G부터 제공되는 정규표현식(Regular Expression)을 이용해 문제를 풀었습니다. 정규식이 아닌 일반적인 방법도 함께 알아보고 문제를 풀기 위해 어떤 개념이 도입되었는지 차근차근 접근해 보도록 하겠습니다.
우선 이 문제는 IP 목록을 정렬하는 문제입니다. 단순하게 IP 로 정렬했을 때 워하는 결과가 나오는지 확인해 보도록 하겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | SELECT ROWNUM rn , ip FROM t ORDER BY ip;-- 실행결과 RN IP--- ----------- 2 10.100.1.10 1 10.100.10.1 3 100.10.1.10 4 100.10.1.20 5 2.10.1.140 |
[리스트3] 의 결과를 확인해 보면 원하는 결과와 다른 것을 알 수 있습니다.
2번으로 시작하는 ip가 먼저 나오길 기대했지만 엉뚱하게도 10번으로 시작하는 ip가 먼저 출력되었으며 심지어는 100번으로 시작하는 ip보다도 나중에 출력이 되었습니다.
문제를 풀기 전에 왜 10 이나 100 이 2보다 먼저 출력되는지를 알아야 합니다. 숫자 비교 시에 2와 10은 10이 당연히 큽니다.
숫자는 그 자체로 크기를 가지고 있지만 문자는 숫자와 달리 크기를 가지고 있지 않기 때문에 앞에서부터 한 글자씩 아스키코드 값으로 비교를 하게 됩니다.
즉 문자 ‘10’ 의 첫 글자는 ‘1’이고 ‘1’은 ‘2’보다 작으므로 ‘10’이 ‘2’보다 작은 값이 되는 것입니다.
이런 이유로 숫자형식으로 설계되어야 하는 테이블을 문자형식으로 잘못 설계할 경우 정렬이 제대로 되지 않는 사례는 아주 흔하게 있는 접할 수 경우입니다.
따라서 순자로 된 비교결과 혹은 정렬결과를 얻으려면 문자를 숫자로 형변환하거나, 또는, 문자의 자리수를 서로 맞추어 비교하면 됩니다. 즉 문자 ‘2’ 와 ‘10’ 비교시 고정자리수 3자리로 맞추어 비교하면, 즉, ‘002’ 와 ‘010’ 과 같이 비교하게 되면 앞글자부터 차례로 비교하므로 ‘002’ 가 ‘010’ 보다 작은 값임을 정확하게 비교할 수 있습니다.
문제로 다시 돌아와서. 문자형에 대한 정렬은 올바른 결과를 낼 수 없으므로, 구분자(.)를 기준으로 4개의 숫자로 나누어 정렬을 한다면 원하는 결과를 얻을 수 있을 것입니다.
그렇다면 구분자를 기준으로 4개의 컬럼으로 데이터를 쪼개려면 어떤 함수가 사용이 되어야 할까요? 구분자의 위치를 알 수 있는 INSTR 함수와 문자열을 잘라내는 함수인 SUBSTR을 적절히 이용한다면 가능한 일입니다.
구분자로 ip를 분리해 내는 쿼리를 만들어 보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SELECT ROWNUM rn , ip , SUBSTR(ip, 1, INSTR(ip, '.', 1, 1) - 1) ip_1 , SUBSTR(ip, INSTR(ip, '.', 1, 1) + 1 , INSTR(ip, '.', 1, 2) - INSTR(ip, '.', 1, 1) - 1) ip_2 , SUBSTR(ip, INSTR(ip, '.', 1, 2) + 1 , INSTR(ip, '.', 1, 3) - INSTR(ip, '.', 1, 2) - 1) ip_3 , SUBSTR(ip, INSTR(ip, '.', 1, 3) + 1) ip_4 FROM t;-- 실행결과 RN IP IP_1 IP_2 IP_3 IP_4----- ----------- --------- ---------- ----------- -------- 1 10.100.10.1 10 100 10 1 2 10.100.1.10 10 100 1 10 3 100.10.1.10 100 10 1 10 4 100.10.1.20 100 10 1 20 5 2.10.1.140 2 10 1 140 |
구분자를 기준으로 4개의 숫자로 분리하는 쿼리[리스트 4]가 완성되었습니다.
이를 숫자로 변경하거나(TO_NUMBER함수 이용), 고정자리수로 변형하거나(LPAD 함수 이용) 한다면 원하는 정렬결과를 얻을 수 있을 것입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | SELECT ROWNUM rn , ip , LPAD(REGEXP_SUBSTR(ip, '[^.]+', 1, 1), 3, '0') ip_1 , LPAD(REGEXP_SUBSTR(ip, '[^.]+', 1, 2), 3, '0') ip_2 , LPAD(REGEXP_SUBSTR(ip, '[^.]+', 1, 3), 3, '0') ip_3 , LPAD(REGEXP_SUBSTR(ip, '[^.]+', 1, 4), 3, '0') ip_4 FROM t ORDER BY ip_1, ip_2, ip_3, ip_4;-- 실행결과 RN IP IP_1 IP_2 IP_3 IP_4----- ----------- ------ ------ ------ ------ 5 2.10.1.140 002 010 001 140 2 10.100.1.10 010 100 001 010 1 10.100.10.1 010 100 010 001 3 100.10.1.10 100 010 001 010 4 100.10.1.20 100 010 001 020 |
구분자를 기준으로 항목을 분리하고 고정자리수로 왼쪽에 0을 채워 정렬하게 되면 원하는 정렬결과를 얻을 수 있게 됩니다. 하지만 INSTR과 SUBSTR의 사용이 상당히 복잡하여 쉽지만은 않습니다.
SUBSTR 대신 REGEXP_SUBSTR 을 이용한다면 좀 더 간단해 질 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | SELECT ROWNUM rn , ip , LPAD(SUBSTR(ip, 1, INSTR(ip, '.', 1, 1) - 1), 3, '0') ip_1 , LPAD(SUBSTR(ip, INSTR(ip, '.', 1, 1) + 1 , INSTR(ip, '.', 1, 2) - INSTR(ip, '.', 1, 1) - 1), 3, '0') ip_2 , LPAD(SUBSTR(ip, INSTR(ip, '.', 1, 2) + 1 , INSTR(ip, '.', 1, 3) - INSTR(ip, '.', 1, 2) - 1), 3, '0') ip_3 , LPAD(SUBSTR(ip, INSTR(ip, '.', 1, 3) + 1), 3, '0') ip_4 FROM t ORDER BY ip_1, ip_2, ip_3, ip_4;-- 실행결과 RN IP IP_1 IP_2 IP_3 IP_4---- ----------- ------ ------ ------ ------ 5 2.10.1.140 002 010 001 140 2 10.100.1.10 010 100 001 010 1 10.100.10.1 010 100 010 001 3 100.10.1.10 100 010 001 010 4 100.10.1.20 100 010 001 020 |
[리스트6]의 쿼리를 실행하면 앞서 [리스트5]의 실행결과와 동일한 결과를 얻을 수 있습니다.
REGEXP_SUBSTR은 정규표현식을 이용한 문자열 잘라내기입니다.
즉, ‘[^.]+’ 는 . 이 아닌 문자가 하나 이상 연결된 패턴을 의미합니다.
뒤에 숫자 (1, 1)은 문자열의 첫 번째부터 탐색하여 1번째 만나는 패턴문자열을 반환하라는 의미입니다. (1, 2)는 두 번째 패턴문자열을 반환하라는 의미가 되겠지요.
[리스트6]이 [리스트5]에 비해 쿼리가 간결해지고 명확해졌습니다.
그러나 여기서 만족 할 수는 없죠. 마지막으로 정답 쿼리를 단계별로 실행해보고 분석해 보도록 하겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | SELECT ROWNUM rn , ip , '.'||ip ip_1 , REPLACE('.'||ip, '.', '.00') ip_2 , REGEXP_REPLACE(REPLACE('.'||ip, '.', '.00'), '([^.]{3}(\.|$))|.', '\1') ip_3 FROM t ORDER BY ip_3;-- 실행결과 RN IP IP_1 IP_2 IP_3----- ----------- ------------ ----------------------- ------------------ 5 2.10.1.140 .2.10.1.140 .002.0010.001.00140 002.010.001.140 2 10.100.1.10 .10.100.1.10 .0010.00100.001.0010 010.100.001.010 1 10.100.10.1 .10.100.10.1 .0010.00100.0010.001 010.100.010.001 3 100.10.1.10 .100.10.1.10 .00100.0010.001.0010 100.010.001.010 4 100.10.1.20 .100.10.1.20 .00100.0010.001.0020 100.010.001.020 |
[리스트6]을 확인해 보겠습니다.
우선 IP의 앞쪽에 '.' 을 붙인 것이 IP_1입니다. 다음 IP_1에서 '.' 을 '.00' 으로 변경한 것이 IP_2입니다. 마지막으로 IP_2에 REGEXP_REPLACE를 이용해 IP_3을 만들어 이를 이용해 정렬을 했습니다.
어떻게 해서 이런 결과가 나오게 되는지 분석해 보겠습니다.
두 번째 단계에서 . 을 .00 으로 변경한 것은 LPAD 기능을 한 번에 구현하기 위함입니다. IP의 숫자는 1자리에서 3자리를 차지하므로 앞에 00 을 붙이면 3자리에서 5자리가 되게 됩니다([리스트6]의 IP_2 항목 참조). 이 상태에 3자리가 넘는 경우 앞의 '0' 을 제거하게 되면 최종적으로 4개의 숫자가 모두 3자리로 고정되게 됩니다.
그렇다면 어떻게 3자리 고정 자릿수 숫자가 완성되게 되었는지 REGEXP_REPLACE 사용부분에대해 살펴보겠습니다.
REGEXP_REPLACE는 정규표현식을 이용해 해당 패턴문자열을 다른 문자열로 대체하는 함수입니다.
IP_2 부분이 변경대상이고, '([^.]{3}(\.|$))|.' 이 부분이 변경할 패턴이며, '\1' 이 부분이 문자가 대체될 부분입니다.
[^.] 은 앞서 설명 드렸듯이 . 이 아닌 문자를 의미하며 {3}은 3개의 문자를 의미합니다.
(\.|$) 괄호 안에서 | 의 의미는 '또는'의 의미입니다. '\.' 은 '.' 문자를 의미합니다.
만약 '.' 을 단독으로 사용한다면 이는 모든 문자열을 의미하므로 단지 '.'만을 표현하기위해 Escape 문자 '\'을 사용했습니다. '$'는 문자열의 맨 마지막을 의미합니다.
'([^.]{3}(\.|$))|.' 이 부분을 해석해 보면 ('.'이 아닌 문자 3개 연속 다음에 '.'또는 문자가 끝나는 경우) 또는 (모든 문자) 을 의미합니다.
확실한 이해를 돕기 위해 색깔로 구별하여 표시해 보겠습니다.
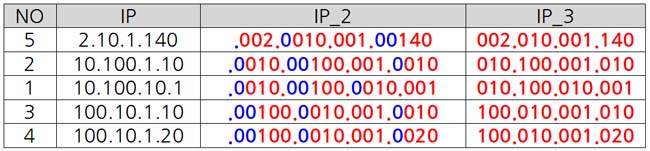
[그림 3]을 확인해 보면 빨간 부분과 파란 부분이 구별되는 것을 확인 할 수 있습니다.
마지막으로 바뀔 문자 즉 대체될 문자로 표현된 '\1'은 앞의 정규표현식중 괄호()록 묶인것 중 첫 번째 괄호를 의미합니다. 첫 번째 괄호는 빨간색으로 표현된 부분이 되겠지요. 즉 빨간색 또는 파란색 문자를 찾아 이를 다시 빨간색 문자열로 대체하겠다는 의미가 됩니다.
결론을 말하자면 파란색을 삭제한다는 의미가 됩니다. 빨간색으로 표현된 첫 번째 패턴문자열만 남기고 파란색으로 표현된 두 번째 패턴 문자를 삭제하여 IP_3과 같은 결과를 얻게 되었습니다.
마지막으로 IP_3 은 조회할 때 필요한 자료가 아니고 정렬할 때만 필요한 자료이므로, 이를SELECT절에서 빼서 ORDER BY절로 옮기면 정답 쿼리가 완성됩니다.
이번 퀴즈에서는 숫자와 문자열간의 정렬 차이에 대한 이해와 문자열로 저장된 숫자를 숫자처럼 정렬하는 방안에 대해 살펴 보았고요. 또한 IP와 같이 숫자들의 연결로 이루어진 문자 열의 정렬을 하는 방법을 알아봤습니다.
앞서 정답을 이끌어 내기 위한 중간단계의 쿼리들([리스트 5], [리스트 6])의 경우엔 IP처럼 4개의 숫자모음인 경우에만 적용이 가능하지만 [리스트 2] 정답 쿼리의 경우는 IP처럼 4개 숫자 고정이 아닌 가변 숫자 목록에 대해서도적용이 가능합니다.
예를 들면 제목에 붙는 숫자 (1, 1.1, 1.2, 1.2.1) 또는 버전에 붙는 숫자 (v1.0, v11.2.0.1.0) 등 다양한 분야에 응용이 가능하므로 알아두시면 좋습니다.
간략하게나마 정규표현식의 사용방법에 대해서도 공부하게 되었는데요. 우리가 이번 퀴즈를 통해 배운 정규표현식은 빙산의 일각에 불과합니다. 정규표현식은 틀에 박힌 고정적인 문자함수 기능보다 더 유연하게 문자의 패턴을 인지하여변화를 줄 수 있는 것으로, 오라클뿐만 아니라 다른 여러 가지 프로그래밍 언어에서도 지원하며, 텍스트 에디터에서도 정규식을 이용한 찾아 바꾸기 기능도 사용이 가능하므로 알아두시면 유용하게 사용하실 수 있으니 따로 찾아서 공부해 보시길 바랍니다.
- 강좌 URL : http://www.gurubee.net/lecture/2195
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.
자세한 설명 감사해요. 많은 도움 받고 갑니다.
정규식에 대한 세세한 설명까지 덧붙여주셔서... 이해는 가지만 역시나 생소하네요.
정규표현식을 이처럼 이해해서 응용할수 있을지..