데이터베이스 노하우/팁/자료실
2024년 5월 23일 PostgreSQL 17 beta 1이 릴리즈 되었습니다. 매년 메이저 버전을 한 개씩 올리는 PostgreSQL의 정책상 사용자에게 더 나은 경험을 제공해 주기 위해 1년간 많은 내용들을 연구하고 적용합니다. 또한 PostgreSQL이 OSS(Open Source Sofrware)이다 보니 다른 기여자들의 참여도 활발하고, 자신이 기여한 내용이 적용된다면 그만한 보람이 또 없을 것입니다.
이 글에서는 이번 PostgreSQL 17 beta에서 어떤 기능들이 집중적으로 조명되었고, 그를 통한 앞으로의 방향에 대해 예측해 보겠습니다.
1) VACUUM 성능 향상
PostgreSQL은 Oracle과 MySQL과는 달리, MVCC를 위한 VACUUM을 적용하였습니다. 보통 Data는 물리적으로 디스크에 저장되는데, 이 데이터를 갱신 시, 디스크에 있던 기존 정보를 갱신하거나 삭제하지 않아, FSM(FreeSpaceMap)에 사용 가능한 공간이 있는지 확인 후 없으면 FSM을 추가로 확보합니다. FSM에서 사용할 수 있는 공간에 UPDATE 된 데이터를 기록, UPDATE된 데이터의 저장이 완료되면 UPDATE 이전 원본 Tuple을 가리키던 포인터를 이동시켜, 어디에도 참조되지 않는 기존 Data, 즉 Dead Tuple이 발생하게 됩니다.
VACUUM이 테이블에서 UPDATE 또는 DELETE로 인해 발생한 Dead Tuple을 처리할 때, VACUUM은 Index Vacuum을 처리하는 동안 테이블에서 해당 Tuple이 어디에 있었는지 기억해야 하는데, 이 원리는 기본 테이블에 데드 튜플, 데드 Row Version이 존재하고, Index가 여전히 해당 Dead Row를 가리키고 있어,인덱스로 이동하여 오래된 인덱스 항목을 제거한 다음 기본 테이블에서 데드 튜플을 실제로 완전히 제거할 수 있어야 합니다. 그러나 PostgreSQL 16버전까지는 이에 할당할 수 있는 용량이 적어(최대 1GB), 성능 측면에서 많은 애로사항이 있었습니다.
이를 해결하기 위해, ID를 저장할 때 간단한 배열을 사용하여 처리, 메모리 효율성이 높아졌습니다. 실제로 pganalyze에서 PG16과 PG17에 대한 autovacuum 기능 테스트 시, PG16은 Index vacuum이 계속 전환되면서 그만큼 IO 접근이 잦아지지만, PG16에서는 그러한 과정 없이 1회의 Scanning Heap만 발생함과 동시에 처리 시간도 빨라지는 결과를 보여주었습니다.
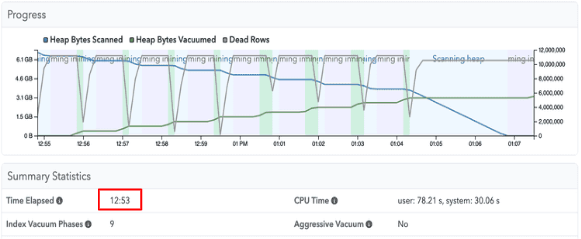
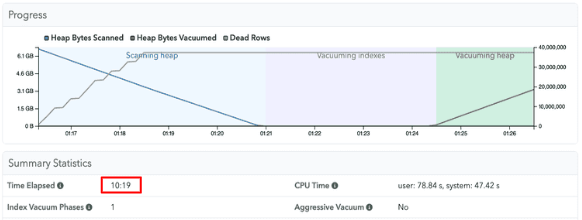
pganalyze>
2) 인덱스 알고리즘 강화를 통한 쿼리 최적화
이번 PostgreSQL 17 beta에서는 B-Tree 및 BRIN 인덱스에 대한 유의미한 성능 강화가 이뤄졌습니다
B-Tree index는 이제 제약 조건이 있는 Row 실행 시 중복된 문을 제거할 수 있으며 더 이상 Row의 절이 포함된 쿼리에 대해 작업을 수행하지 않습니다. 이전 버전인 PostgreSQL 16은 한 번에 여러 값을 제어할 수 없어, 커밋 전에 B-Tree Index를 반복적으로 탐색하여 동일한 페이지를 얻어냈었으나, 이제 특정 페이지로 작업할 때 이 입력 값 배열이 고려되므로 전체 트리를 다시 탐색하지 않고도 다음 값을 얻을 수 있게 되는 이점이 생겼습니다. 여러 값이 포함된 IN 절은 각 값에 대해 인덱스 스캔 카운터가 증가하였으나, 이번 기능 개선을 통해 이 카운터가 크게 감소하는 이점을 볼 수 있게 되었습니다. 또한 BRIN 인덱스에 병렬 Index Build 사용을 지원하게 됨으로써, 여러 병렬 작업자를 사용하여 인덱스 생성 시간을 크게 단축시킬 수 있어, 대규모 데이터셋에서 효율적으로 인덱스를 생성할 수 있게 되었습니다.
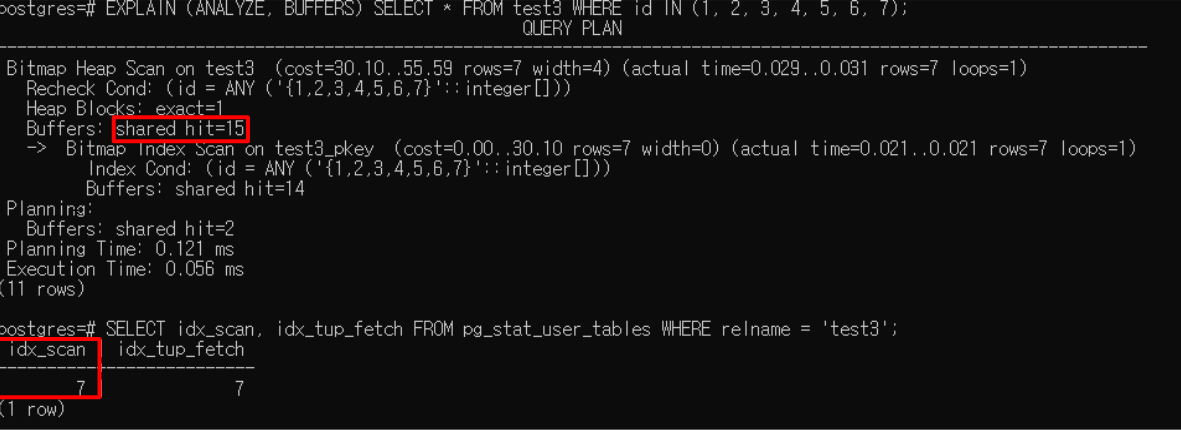
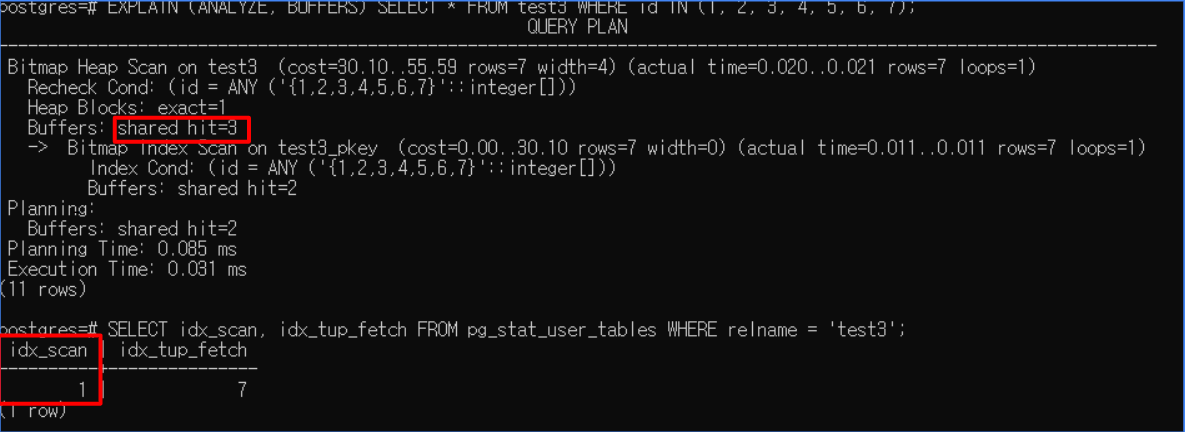
<10만개의 데이터를 IN절을 통해 검색했을 때의 PG16(상)과 PG17(하)의 쿼리 플랜 비교>
3) Logical Replication
기존에는 최신 버전으로 업그레이드 할 경우, 기존의 Logical Replication Slot을 삭제하는 번거로움이 존재하였는데, 이제는 삭제할 필요 없이 바로 업그레이드를 진행할 수 있게 되었습니다. 이로 인해, 엔지니어는 이제 업그레이드에만 집중할 수 있게 되었습니다. 또한, 장애 조치를 제어할 수 있는 기능이 추가되었습니다.
Physical Replication과 Logical Replication은 사상적 차이가 존재합니다. 특히 그 중 Physical Replication은 DB의 버전이 다를 경우 Replication 자체가 이뤄지지 않는데, 이번 기능 개선을 통하여 Physical 기준으로 복제된 내용을 새로이 Logical 복제본으로 변환할 수 있는 CLI가 추가되었습니다. 엔지니어 입장에서 좀 더 쉬운 HA 제어가 가능해 졌습니다.
4) JSON 강화
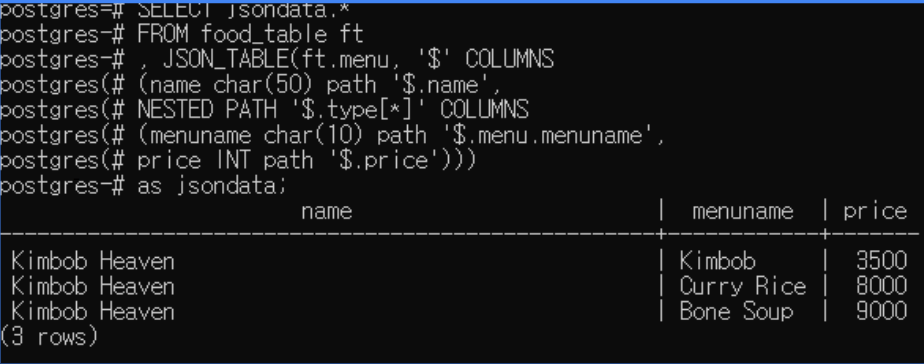
기존의 PostgreSQL이 JSON을 제어할 수 없었던 것은 아닙니다. 하지만 JSON을 다루기 위해 각 행에 대한 여러 타입 캐스팅을 진행해야 했고, 그에 따른 쿼리가 번거로워짐을 감수해야만 하였습니다. 그래서 Oracle이나 MySQL의 JSON_TABLE()을 부러워했던 경우가 많았습니다.
그러나 이제 PostgreSQL에서도 JSON을 표준 PostgreSQL 테이블로 변환할 수 있는 기능과 SQL/JSON 생성자 및 쿼리 함수에 대한 지원이 추가되었습니다. 원래는 PostgreSQL 15에 릴리즈 하려 했으나, 베타 기간에 잠깐 나왔다 사라졌습니다. 이로써 JSON_TABLE() 및 JSON(), JSON_SCALAR() 및 JSON_SERIALIZE() 같은 SQL/JSON 생성자 function이나 JSON_EXISTS(), JSON_QUERY() 및 JSON_VALUE() 등의 쿼리 Function을 지원합니다. 단,
이번 beta 버전에서는 JSON_TABLE()이 중첩 열을 처리하는 기능은 없이 제공될 예정입니다.
5) 앞으로의 방향성은?
그 외에도 여러 가지 개선 사항이 있었습니다. MERGE를 통한 뷰 업데이트 COPY의 처리 속도 향상, 증분 백업 및 I/O 모니터링 시 소모 시간 표시 등 많은 기능들이 들어왔습니다.
1997년 PostgreSQL 6.0이 태동한 이후, 약 27년이 지났습니다. 개발자 친화적인 모토를 가지고 지속적인 기능 강화가 이루어지고 있는 이 때, 대부분의 업데이트에서 인덱스 강화, Logical Replication 강화 등이 이뤄졌으며, 최근 16 버전에서는 JSON/JSON 표준을 준수하는 정책이 도입되었습니다. 특히 금번 업데이트 중 인덱스를 개선하기 위한 적응형 기수 트리가 추가되거나, Logical Replication의 강화, JSON function 지원 등을 통해 DB 자체의 퍼포먼스를 강화하는 동시에 좀 더 고품격의 HA를 보장하고, JSON에 대한 사용자의 목마름을 해소할 수 있는 첩경을 제시함으로써, 상기 기능을 중점으로 강화하며 발전하지 않을까 하는 추측을 해봅니다.
앞으로도 PostgreSQL이 개발자 뿐만아니라 사용자에게 만족감을 줄 수 있는 긍정적인 방향으로 발전하기를 기대해 봅니다.
>> 참고: 비트나인 블로그